400-123-4657


作者:佚名 时间:2024-04-07 23:23:42
先回答第二个问题:怎么样选择用哪种算法来进行优化?
最快速的方法,搜索具体问题的相关论文或类似问题的相关论文,统计一下大家使用的方法,选取使用最多的方法就比较有保障。
或者,最有效的方法,采用不用方法进行求解,然后对比分析选取效果最好的方法。
第一个问题:
智能优化算法学习笔记优化问题在背包问题、数据聚类、数据分类、路径规划、机器人控制等工程应用中普遍存在。
群体智能(Swarm Intelligence,SI)优化算法通过在搜索过程中引入随机性,避免在处理复杂问题时陷入局部最优解,因而成为解决全局优化问题的主要方法。
麻雀搜索算法(Sparrow search algorithm)是Xue等人受麻雀觅食和反捕食行为的启发,提出了一种新的群体智能优化算法。
众所周知,麻雀是群居、杂食性的常驻鸟类,它们非常聪明,记忆力也很强。将麻雀分为两种类型:一种是生产者,一种是乞讨者。生产者可以主动寻找食物来源,而乞讨者则跟随生产者获取食物,两种类型的麻雀也可以互换身份。麻雀个体的能量储备影响麻雀觅食策略,能量储备较低的麻雀更加主动去觅食。另外,麻雀也是一种警惕性较强的动物,当某个麻雀发现捕食者时,一只或者多只麻雀发出一声啁啾,整个鸟群便飞走了。
将麻雀的各种觅食行为抽象化,并制定了相应的规则。
① 生产者具有高水平的能量储备,并为所有乞讨者提供觅食区域或方向。它负责识别能找到丰富食物来源的区域。能量储备的水平取决于个体的适应度值的评估。
② 一旦麻雀发现捕食者,它们就开始叽叽喳喳地叫,发出警报信号。当报警值大于安全阈值时,生产者需要将所有的麻雀引导到安全区域。
③ 只要寻找更好的食物来源,每只麻雀都可以成为生产者,但在整个种群中,生产者和乞讨者的比例不变。
④ 一些饥饿的乞讨者更有可能飞到其他地方去寻找食物,以获得更多的能量。
⑤ 乞讨者跟随能提供最好食物的生产者寻找食物。与此同时,为增加自己的捕食率,一些乞讨者可能会不断监视生产者,争夺食物。
⑥ 处于群体边缘的麻雀在意识到危险时,会迅速向安全区域移动,以获得更好的位置,而处于群体中间的麻雀则会随机行走,以接近其他麻雀。
2. 数学模型
在数学模型中,各个麻雀的位置可以以下面的矩阵来表示:
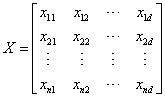
其中,n为麻雀的数量,d为待优化变量的维数。
所有麻雀的适应度可以由下列向量表示:
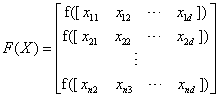
其中n为麻雀数量,F(X)每一行的值代表个体适应度的值。
生产者:
生产者作为整个麻雀种群的向导,能够比乞讨者在更广泛的范围内寻找到食物。根据规则(1)和(2),在每次迭代中,生产者的位置更新如下:
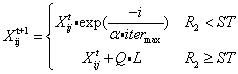
α是一个随机数,α∈[0,1]。R2∈[0,1]是指报警值,ST∈[0.5,1]是安全阈值。Q是一个服从正态分布的随机数,L是每个元素全为1的d维行向量。
当时,R2<ST说明麻雀种群周围没有捕食者,生产者进入广泛搜索的模式;当R2≥ST时,说明种群周围发现捕食者,所有麻雀需要飞到安全区域。
乞讨者:
如规则(4)和规则(5)所示,一些乞讨者会频繁地监视生产者,当生产者寻找到更好的食物来源时,它们会离开目前的位置前去争夺食物,若它们赢得胜利,则立即得到生产者的食物;否则会继续执行规则(5)。乞讨者的位置更新公式如下:
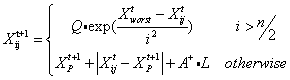
A是一个d维行向量,其中的元素值被随机地分配为1或者-1,且A+=AT(AAT)-1。当i>n/2时,这表明适应度值较差的第i个乞讨者最有可能挨饿。
警戒者:
根据规则(6),我们假定警戒者占麻雀总数的10%~20%,它们最初的位置是在种群中随机产生的。其数学模型可以表示为:
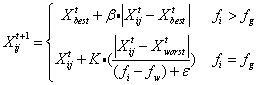
B是步长控制参数,是一个服从N(0,1)的随机数;K∈[-1,1]是一个随机数,fi是当前麻雀的适应度的值,fg和fw是当前的全局最佳和最差的适合度值。ε是一个非常小的常数,以免零作除数。
简单来说,fi>fg表示麻雀在种群的边缘,而Xbest表示麻雀种群的中心位置,它的周围是安全的。fi=fg表示麻雀种群中心的麻雀意识到了危险,需要向其他麻雀的位置移动,K即麻雀的运动方向,也是步长控制系数。
伪代码:

3. 实验验证

函数F1:
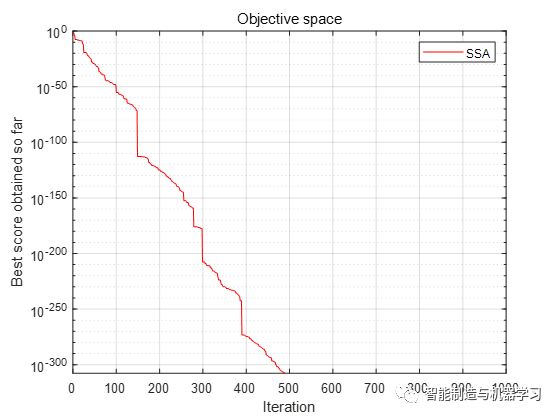
函数F2:
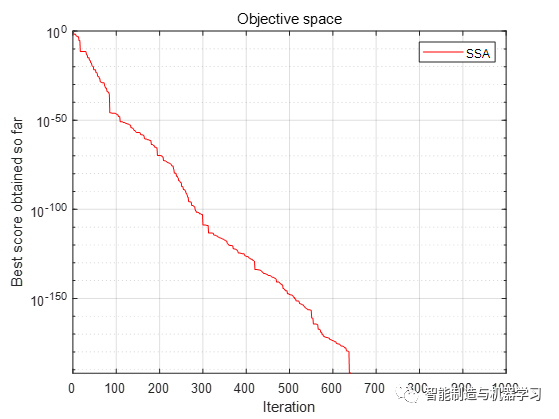
函数F3:
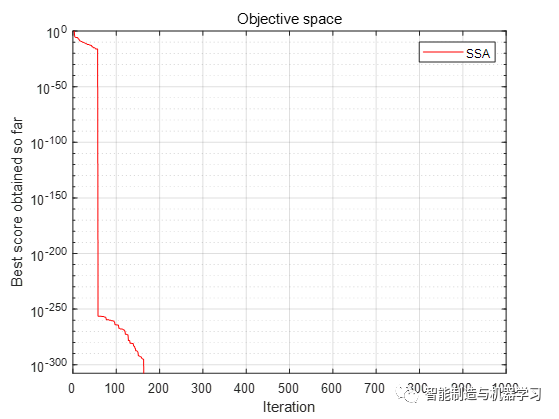
函数F4:
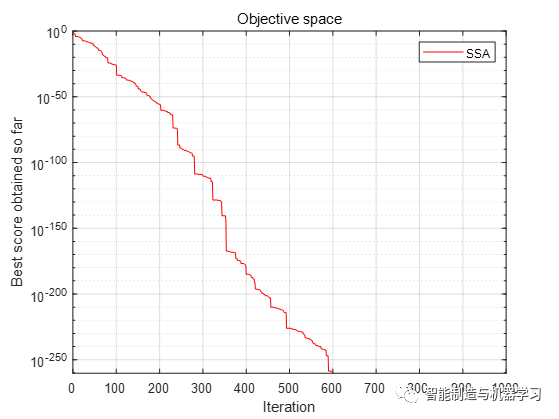
函数F5:

函数F6:
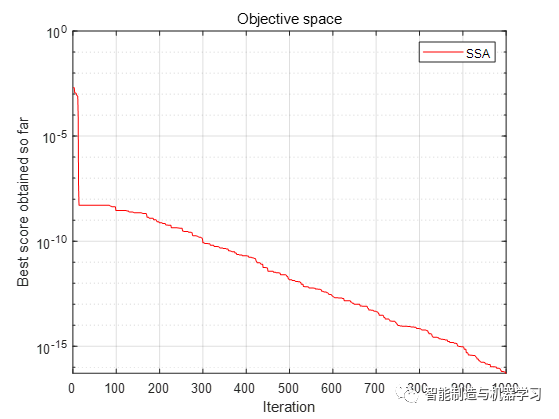
参考文献:
Jiankai Xue & Bo Shen (2020) A novel swarm intelligence optimizationapproach: sparrow search algorithm, Systems Science & Control Engineering, 8:1, 22-34, DOI:10.1080/21642583.2019.1708830
可以考虑试试最新的群智能优化算法:蜣螂优化算法,亲测效果不错
CEC2017中的测试
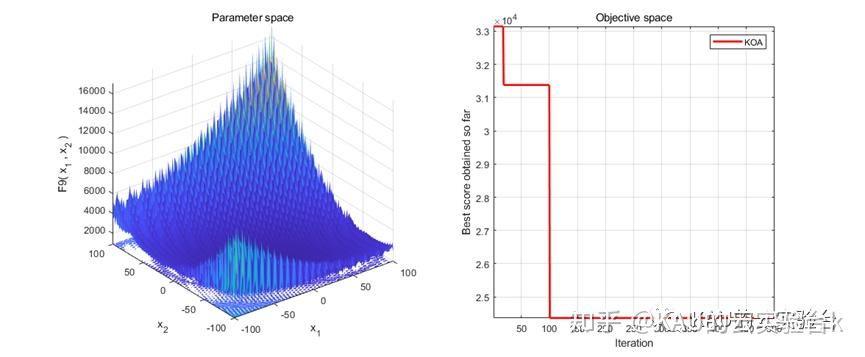
本文作者将介绍一个2023年发表在中科院1区期刊《Knowledge -Based Systems》上的优化算法——开普勒优化算法(Kepler optimization algorithm,KOA)[1]

算法性能上,与鹈鹕、黏菌、灰狼和鲸鱼等一众优化算法在CEC2014、CEC2017、CEC2020和CEC2022上进行了测试,均显示出其惊艳的性能。因此,感兴趣的各位就和作者一起学习一下该算法的巧妙之处吧,并且,在文章的最后也给出了算法的MATLAB和Python实现。将这样性能较好的新算法应用于一些工程问题也能够在一定程度上提升文章的创新性。

00 目录
1 开普勒优化算法(KOA)原理
2 代码目录
3 算法性能
4 源码获取
01 开普勒优化算法(KOA)原理
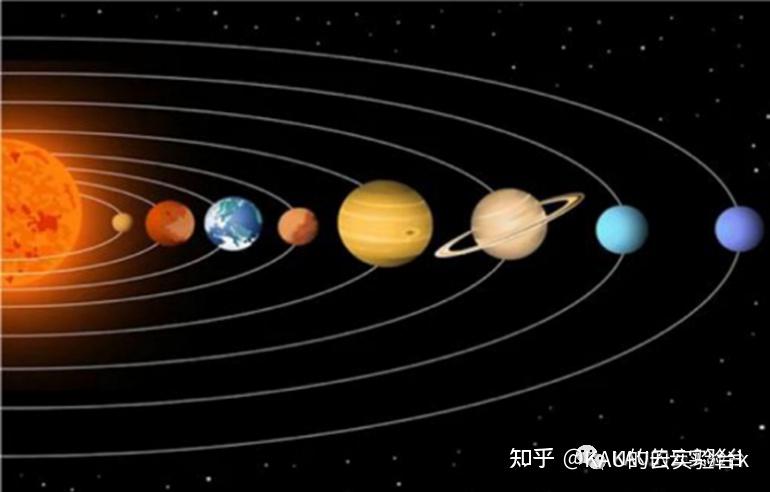
图源文献[1]
KOA为基于物理的优化器(意味着公式会比较多…作者这里就列出核心公式来帮助大家理解),是受开普勒行星运动定律启发的新型优化算法。太阳(最优解)和在椭圆轨道上绕它旋转的行星(候选解)构成了搜索空间,在不同的时间,行星将处于轨道中的不同位置,这种策略有效的执行了勘探与开发(如下)。太阳与行星的吸引力、旋转速度等因素也共同决定了行星与太阳的接近程度。为适配该算法,术语“时间”将更适合迭代一词。

图源文献[1]
1.1 初始化
KOA的种群初始化与其他算法相同,每个行星将放置在轨道上的随机位置,算式为xi=lb+rand*(ub-lb)。除此之外,KOA还有两个新的参数需要初始化,即轨道偏心率e和轨道周期T,其计算:
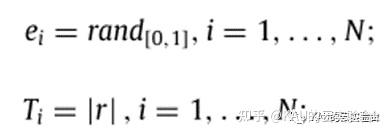
其中,rand为随机值,r为正态分布的随机数。ei与后文中的引力有关,能够赋予KOA一定随机性。而T与椭圆轨道半长轴长度有关,而半长轴长度将随着时间逐渐减小,对应的解也将向可能找到全局最优解的有希望区域移动。
1.2 天体速度
天体的速度受太阳的引力影响,当一颗行星靠近太阳时,它的速度会增加,当它移得更远时,它的速度会降低。如果行星靠近太阳,那么太阳的引力就会相当强,行星就会试图增加自己的速度,以避免被拉向太阳。然而,如果一个物体远离太阳,那么它的速度就会减慢,因为太阳的引力很弱。其关系可由下列方程表示:
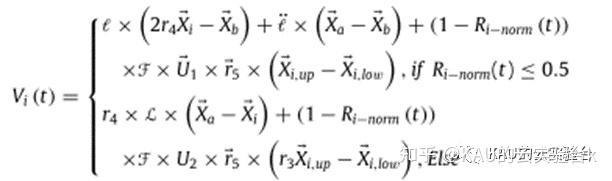
其中具体参数的意义这里不作详解,但可以看到这个公式根据与最优解的距离进行了勘探与开发之间的转换。
1.3 跳出局部最优
在太阳系中,大多数天体都是逆时针绕太阳旋转,它们都绕着自己的轴旋转;然而,也有一些天体是顺时针绕太阳旋转。该算法利用这种行为来逃避局部最优区域,即通过使用标志F(即1.2中的F),改变搜索方向,使代理能够准确地扫描搜索空间。
1.4 更新天体位置
天体在各自的椭圆轨道上围绕太阳旋转。在旋转过程中,物体在一定时间内向太阳靠近,然后远离太阳。KOA通过两个主要阶段模拟这种行为:探索和开发阶段。KOA探索远离太阳的行星以寻找新的解决方案,同时更准确地使用靠近太阳的解决方案,因为它在最佳解决方案附近寻找新的地方。图4显示了太阳周围的勘探和开发区域。
图源文献[1]
行星的位置使用下式更新:
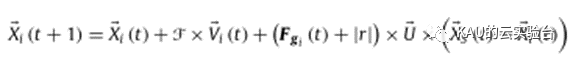
当行星远离太阳时,行星的速度将代表KOA的探索算子。然而,这个速度受到太阳引力的影响,这有助于当前行星略微利用最佳解附近的区域。与此同时,当行星接近太阳时,它的速度急剧增加,使其能够逃脱太阳的引力。在这种情况下,如果迄今为止最好的解(称为太阳)是局部最小值,则速度表示局部最优避免,并且太阳的引力表示利用算子以帮助KOA攻击迄今为止最好的解以找到更好的解。
其中,太阳通过引力控制行星以椭圆的形式绕着其运动,遵循万有引力定律,其定义式:
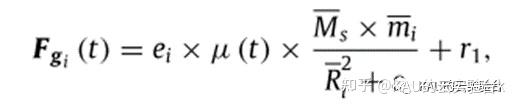
1.5 更新与太阳的距离
为进一步改善行星的探索与开发,算法模仿了太阳与行星之间的距离的典型行为,当行星靠近太阳时,KOA将专注于优化开发算子;当远离太阳时,KOA将优化探索算子。而规则的转换将取决于调节参数h,其随时间逐渐变化。h如下:
图源文献[1]
当h被设置为一个高值时,重点放在探索算子上,导致行星和太阳之间间隔扩大。相反,当h假设一个低的值,倾向于开发,使得能够在迄今为止获得的最佳解附近进行集中探索。
该原理的数学模型描述如下:
1.6 精英保留
该步骤相当于贪婪策略,若位置更新后适应度更佳则保留。
1.7 算法流程
1.8 算法利用
其实在15年和22年都有文献将开普勒混合于优化算法中来提升性能,但这些算法运用的只是开普勒第一定律,形式如下:
其简化程度高,是通过将太阳位置乘均匀分布的伪随机数或通过在太阳位置和行星之间添加距离分量来集中搜索。而在KOA中是一个完整的优化框架,能够更有效的利用和探索空间。其天体位置更新中,既有能够跳出局部最优的策略,也能够进行勘探与开发之间的有效转换,可以将其考虑引入其他算法提升性能。
02 代码目录
代码包含MATLAB和Python以及KOA算法源文献,考虑到很多同学获取代码后,MATLAB代码部分有乱码(MATLAB版本问题),可以将MATLAB版本改为2020及以上,或使用乱码解决文件夹中的txt文件即可。
代码都经过作者重新注释,代码更清爽,可读性强。
部分代码:(MATLAB与Python)
03 算法性能
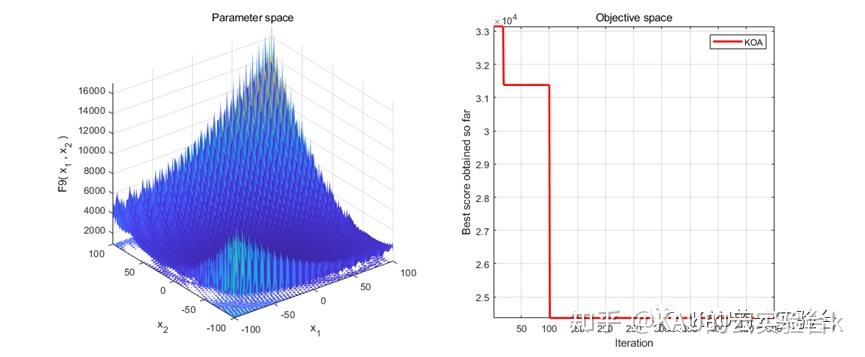
采用标准测试函数初步检验其寻优性能
在MATLAB中,进行CEC2017函数的测试,执行程序结果如下:
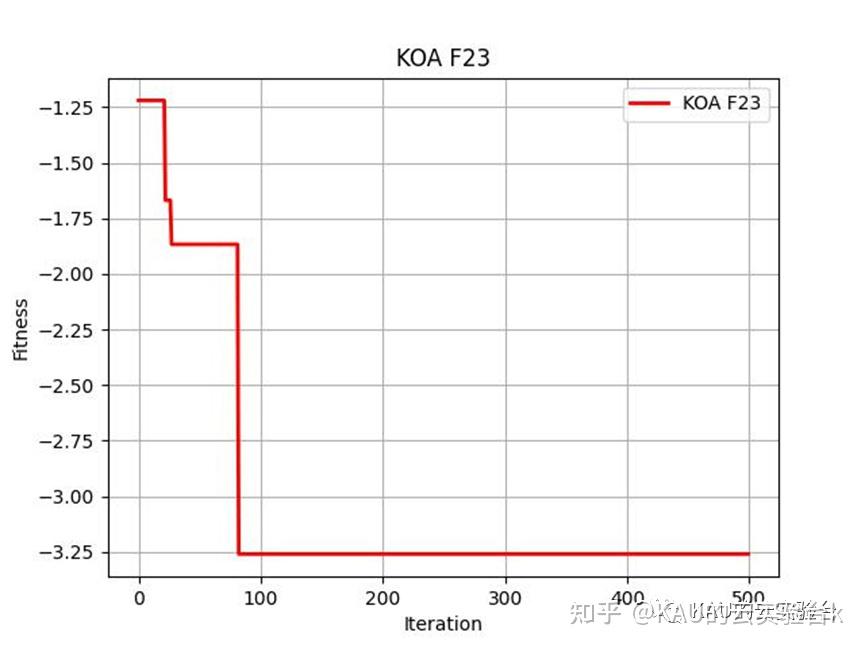
在Python中,进行CEC2005函数的测试,执行程序结果如下:
04 源码获取
在GZH(见简介)后台回复 KOA 即可
参考文献
[1]Abdel-Basset, M. et al. Kepler optimization algorithm: A new metaheuristic algorithm inspired by Kepler’s laws of planetary motion. Knowl. Based Syst. 268, 110454 (2023).
另:如果有伙伴有待解决的优化问题(各种领域都可),可以发我,我会选择性的更新利用优化算法解决这些问题的文章。
如果这篇文章对你有帮助或启发,可以点击右下角的赞/在看(? _)?(不点也行),你们的鼓励就是我坚持的动力!若有定制需求,可私信作者。


