400-123-4657


作者:佚名 时间:2024-04-29 03:56:39
因为曾经从事DB2内核开发工作,所以一直想写一篇关于DB2优化器相关的文章。DB2和Oracle数据库一样,作为老的企业级数据库的代表,从诞生到现在已经多年了。
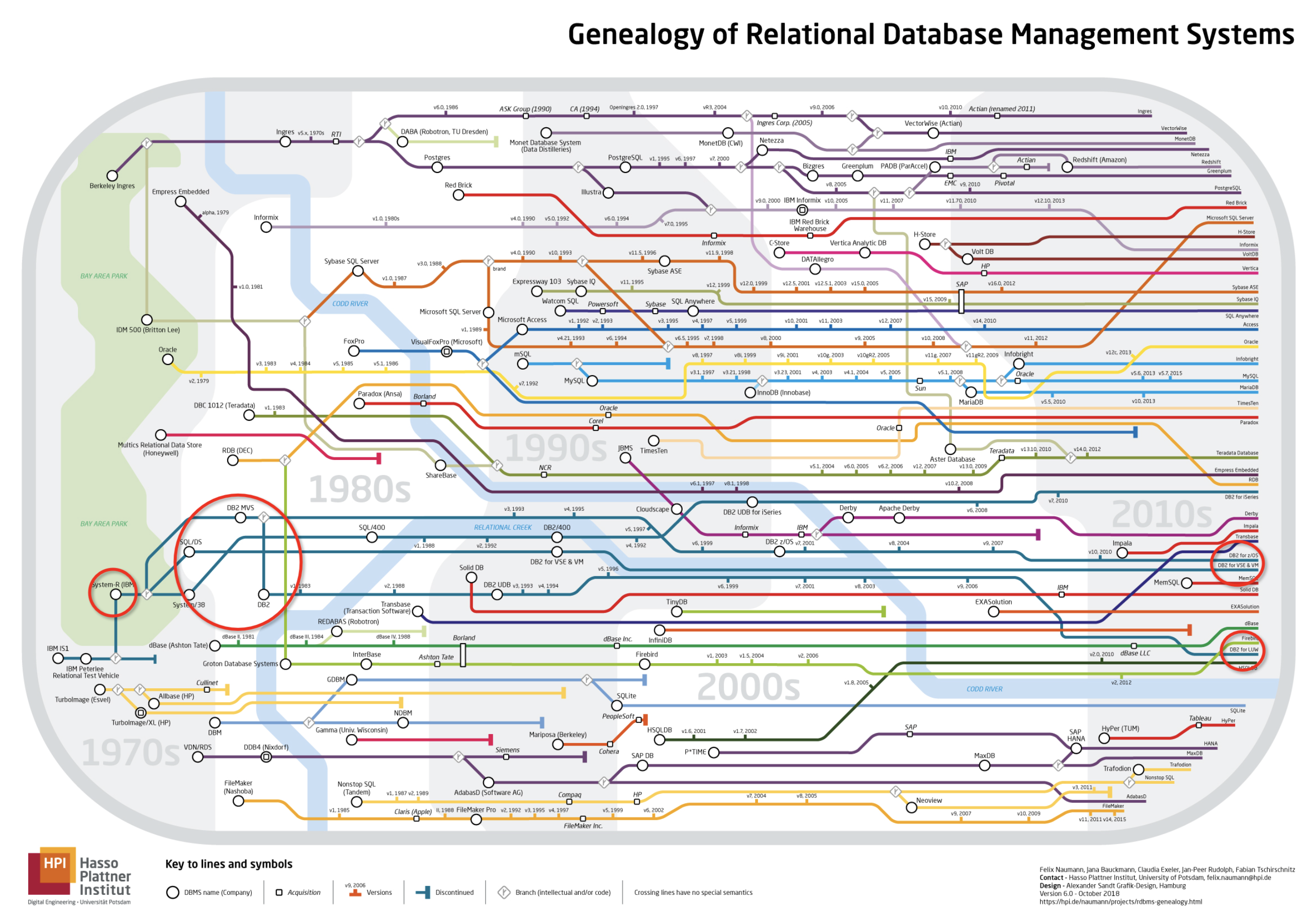
1973年,IBM研究中心启动System R项目,为DB2的诞生打下良好基础。System R 是 IBM 研究部门开发的一种产品,这种原型语言促进了技术的发展并最终在1983年将 DB2 带到了商业市场。在这期间,IBM发表了很多数据库领域的精典论文《A Relational Model of Data for Large Shared Data Banks》 E.F.Codd、《The notions of consistency and predicate locks in a database system》Jim Gray。1981年, E.F.Codd因为发明关系数据库模型,获得ACM图灵奖,当然他前边还有一位大师,Charles W.Bachman。1982年,IBM发布SQL/DS for VSE and VM,以System R为原型。1983年,发布Database2 (DB2) for MVS, 内部代号为"Eagle",于是 DB2正式诞生。
早期数据库遇到的问题和现在云原生数据库遇到的问题有所不同,都是0-1的问题,例如:
DB2设计了一套可以将查询语言转换成执行的框架

可以看到,DB2和现在的常见开源数据库一样,分为Complie和Run-time也就是我们常说的优化阶段和执行阶段,分为6大模块:
当然这里面还缺一些和联邦能力相关的两个模块,下推分析模块PushDown Analyze(PDA)和远程SQL生成remote STatement Generator(STG)
一个简单查询的Physical Executable Plan的样子如下

图左边和右边分别还有两个工具db2exfmt(查看查询优化执行计划中的全部信息)和db2expln(查看执行计划),这里也举两个例子:
DB2 Query Graph Model(QGM)
QGM作为数据库优化器中最重要查询SQL的结构,类似于我们常常提到的AST。QGM主要是为了获取整个SQL查询如何被编译过程存放的信息,有自己的实体关系模型(Entity-Relationship (ER) model),如:
数据流模型中的对象:
节点(Boxes (nodes),代表table operations) 行数据流(Rows flow)
通过这种结构可以轻松的扩展SQL(i.e. SELECT over IUDs)
每个原始表和上层的查询块都叫做Box,让我们看看QGM的实际样子:

简单分析这个初始的QGM,Box#1, #2是基本表(Base table)inventory和quotations。Box#3,#4是查询节点(SELECT box),一个是主查询,一个是子查询。每一个Box包括一个头(Head)和主体(Body),而Body中指定了输出数据表的操作,对于基础表可以是空的或者不存在的Body。我们来看下Box#3,Head包括了SELECT list中的输出列partno、descr和suppno的名字、类型和排序信息。其中还有一个布尔变量distinct来指定是否输出要求不重复 (head.distinct = TRUE)。Body包含了一个图,顶点(vertices)代表量化元组的变量叫quantifiers,可以看到Box#含有三个quantifiers,分表是q1,q2,q4。q1、q2通过Box间的连接(range over操作)关联Box#1,#2基础表inventory和quotations的Head。q1和q2之间的连接代表了连接条件(Join predicate)。q1(F),q2(F),q3(F)和q4(A)中的F代表是该quantifiers来自FROM子句,A代表来自ALL子查询,如果是表存在的谓词 EXISTS, IN, ANY和SOME,那可以用E表示。看Box3和Box4,可以看到Body中也会有distinct属性,但是是枚举类型,包括ENFORCE, PRESERVE or PERMIT:ENFORCE代表必须要进行去重操作去满足head.distinct=TRUE。PRESERVE代表操作可以保留重复数据,因为head.distinct=FALSE或者虽然head.distinct=TRUE但是输出的操作本身是没有重复数据的,不需要去重。PERMIT代表去不去重都可以,比如对于Box#4来说,E和A quantifiers总是设置为distinct = PERMIT的,因为他们对重复数组无感知的。
下面我们利用另外一个简单的SQL,介绍下实体和关系:

QTB (Query TaBle) :QGM中主要是围绕这tables来展开的,tables可以是基础表或者派生表(该派生是更广义的概念,并不是光指View),我们已经叫做Box了,在图中的青色部分。
QCL (Query CoLumn) :通过QTB,我们可以找到对应的列,在图中是蓝色部分。
OPR (OPeRation) :如果QTB本身是派生表,必须有一个操作符OPR,否则就是基础表,类型有SELECT, PROJECT, JOIN, GROUP BY, INSERT等等,图中是紫色部分。
QUN (QUaNtifier):简单理解可以认为是来自于FROM子句的相关名字,来源于表,图中是绿色部分。
QNC (QuaNtifier Column) :从QUN中获取的QTB上的列,图中是褐色部分。
FTB (Fetched TaBle) :表元数据信息。
FCS (Fetched Column Structure) :列元数据信息。
PRD (PReDicate) :返回布尔值的关系符,图中是蓝色部分。
EXP (EXPression):任意的表达式,可以是Head EXP,图中是蓝色部分。
下面图表示了QGM的E-R实体关系:
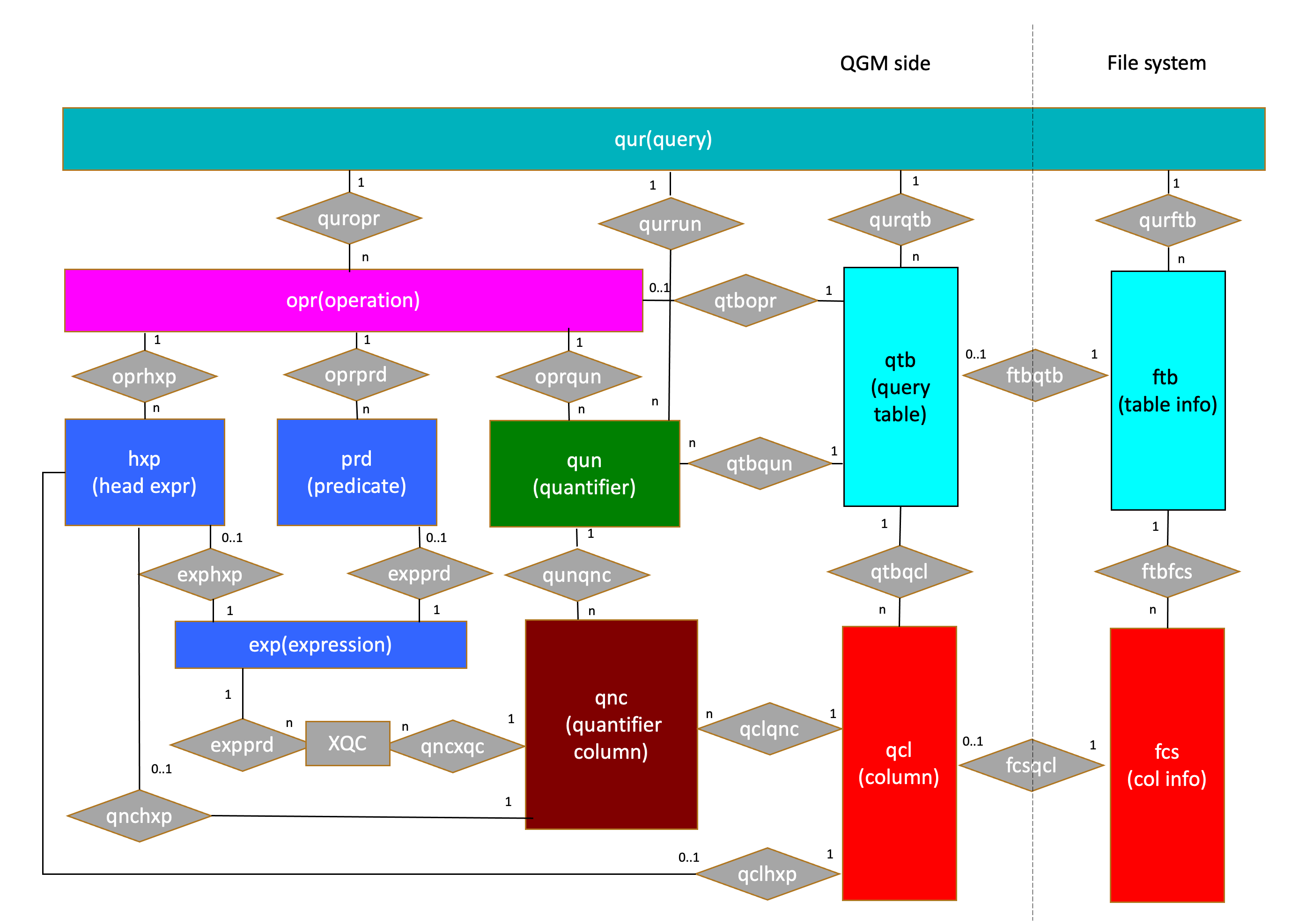
看起来很复杂,其实是如何通过指针从一个实体找到其他实体,比如如果找查询语句qur中的prd,就是通过qur->quropr->oprprd找到的。
我们都知道我们常常把查询语句的变化叫做Query Rewrite而把计算访问方式、连接方式和连接顺序叫做Plan Optimization。相信大家已经了解查询重写就是将已有查询通过数据库内部的变化,转换成等价的更为高效的查询语句。简单来说,比如在一条语句中包含同样的查询,复杂查询通常有很多多余的结构,特别是有视图View的时候,有些自动生成SQL的工具生成的SQL执行效率不是很高,另外也无法手工调优。
关于DB2的优化器实现初期,有个流传已久的有趣故事,当年两位优化器的大牛(抱歉我没有记住)讨论DB2的优化器如何实现的时候,他们针对于使用统一优化器框架到底用Query Rewrite的RULE框架还是Plan Optimization的框架吵的不可开交,谁也不服谁,最后定为分开两个模块各自负责各自的。我们先来看看DB2的基于RULE框架的查询重写是怎么实现的。
DB2的查询重写框架来自于Starburst 研究项目,包含了一个基于RULE的引擎,可以将初始的QGM转为更高效的QGM,有些转换不一定总是通用,有一堆RULES去迭代知道没有可用的RULE或者预算(budget)已经超了。该基于RULE的查询重写引擎一定要遵循:

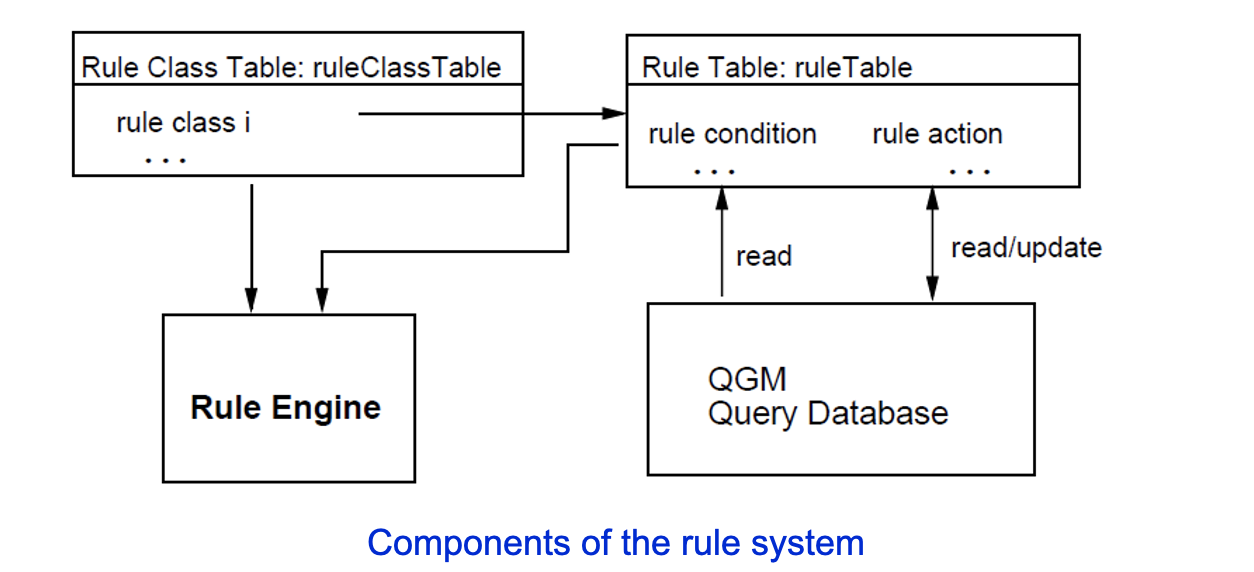
Rules包含两个标准C函数:condition函数,经过条件判断返回TRUE或者FALSE和Action函数,当condition返回TRUE后执行action来对QGM进行改变。
一个数据上下文结构,可以在RULE系统间进行信息传递,比如包括QGM的a box, quantifier, or predicate,每个RULE都可能对该内容进行改写。
Rule分类,是将一些Rule组成一个集合,一个是更好的理解这组Rule的行为,二是一个Rule可以调用另外一个Rule增加了模块化和可理解性,最后还能解决冲突。目前DB2的RULE框架包含了两个schemas,一个是按顺序(sequential scheme),一个是按优先级(priority scheme)。比如下图是Rules依赖关系图:
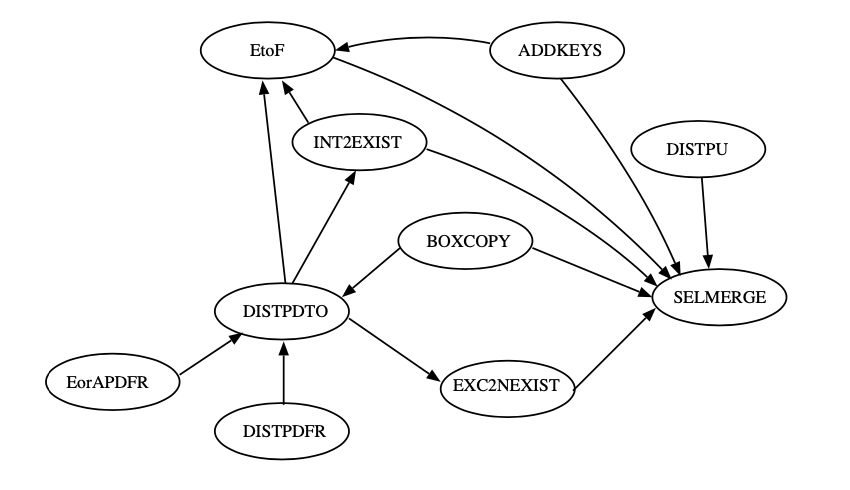
该图展示了如何进行“SELECT merge”(SELMERGE) rule来解决合并SELECT boxes的Rule依赖关系。箭头代表了直接的依赖关系图和执行下一条Rule的传递。
DB2中的Rule classes至少有16种,例如下面举例说明调用关系:

DB2的Rule Engine可以在使用一系列的RULEs后,将会终止该优化过程,即通过是否还有剩余Rules和Buget来控制终止。
rule# |
condProc |
actionProc |
costc |
costa |
sequence number |
0 |
c0 |
a0 |
1 |
1 |
0 |
1 |
c1 |
a1 |
1 |
5 |
1 |
2 |
c2 |
a2 |
1 |
10 |
2 |
step |
selected rule# |
new state |
remaining budget |
comments |
||
rule 0 |
rule 1 |
rule 2 |
||||
active |
active |
active |
20 |
initial state |
||
1) |
0 |
active |
active |
active |
18 |
rule 0 succeeded |
2) |
1 |
active |
blocked |
active |
17 |
c1.outcome=false |
3) |
2 |
active |
active |
active |
6 |
rule 2 succeeded. rule 1 becomes active |
4) |
0 |
active |
active |
active |
4 |
rule 0 succeeded |
5) |
1 |
active |
spent |
active |
4 |
rule 1 needs a budget of 6 |
6) |
2 |
active |
spent |
spent |
4 |
rule 2 needs a budget of 11 |
7) |
0 |
blocked |
spent |
spent |
3 |
c0.outcome=false |
NOTE:如果设置IterMax=1, 那该优化到step 3)就停止了
rule# |
condProc |
actionProc |
costc |
costa |
sequence number |
0 |
c0 |
a0 |
1 |
1 |
0 |
1 |
c1 |
a1 |
1 |
5 |
1 |
2 |
c2 |
a2 |
1 |
10 |
2 |
step |
selected rule# |
new state |
remaining budget |
comments |
||
rule 0 |
rule 1 |
rule 2 |
||||
active |
active |
active |
25 |
initial state |
||
1) |
0 |
blocked |
active |
active |
23 |
a0.outcome=false |
2) |
1 |
blocked |
blocked |
active |
22 |
c1.outcome=false |
3) |
2 |
active |
active |
active |
11 |
rule 2 succeeded & rule 0 is seleted next |
4) |
0 |
blocked |
active |
active |
10 |
c0.outcome=false |
5) |
1 |
active |
active |
active |
4 |
rule 1 = succeeded |
6) |
0 |
blocked |
active |
active |
3 |
c0.outcome=false |
7) |
1 |
blocked |
spent |
active |
3 |
rule 1 needs a budget of 6 |
8) |
2 |
blocked |
spent |
spent |
3 |
rule 2 needs a budget of 11 |
DB2的Rule Engine可以随时控制enable或者disable这些rules,这样也可以去追踪和解析这些rules。
RULE 举例介绍
由于DB2的Rules有90+,这里就简要围绕SELMERGE和相关依赖RULE进行介绍,详细内容可以参考引用中的论文介绍。
SELMERGE(Select Merge) RULE

RULE merge带来的性能提升极大,当然MySQL也有同样的Query Rewrite叫merge_derived。
Query |
CPU Time |
Elapsed time |
Before Rewrite |
20 min 34.51 sec |
24 min 19.80 sec |
After Rewrite |
0 min 1.10 sec |
0 min 7.20 sec |
SELMERGE RULE将两个带有F的Boxes合并成一个Box,当然根据上面的依赖关系图,可以知道,SELMERGE依赖于很多前序的RULE,比如DISTPU。
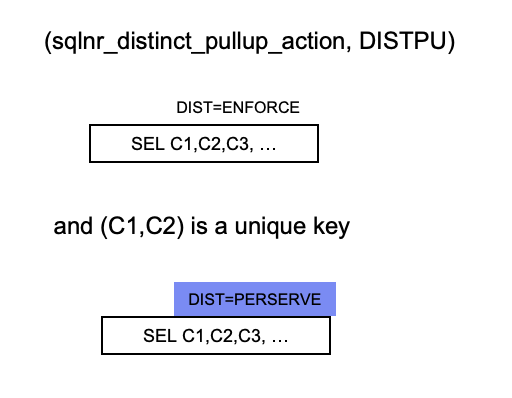
DISTPU(Distinct Pullup)

根据满足条件的quntifier-nodup-condition或者one-tuple-condition的情况直接设置box的head的distinct为TRUE,而去掉body中的distinct属性,例如:SELECT INTERSECT ALL, EXCEPT ALL 和 GROUP BY boxes。
DISTPDFR/DISTPDTO(Distinct Pushdown From/To)

一个Box通知下面的Boxes可以不一定减少重复值,强制讲属性distinct从自身到下面的Boxes,这样可以使下层不一定为了去重而做排序或者Hash,也可以让下层的Boxes使用那些引入重复值的RULEs,下图形象的展示了该rules的转换过程:
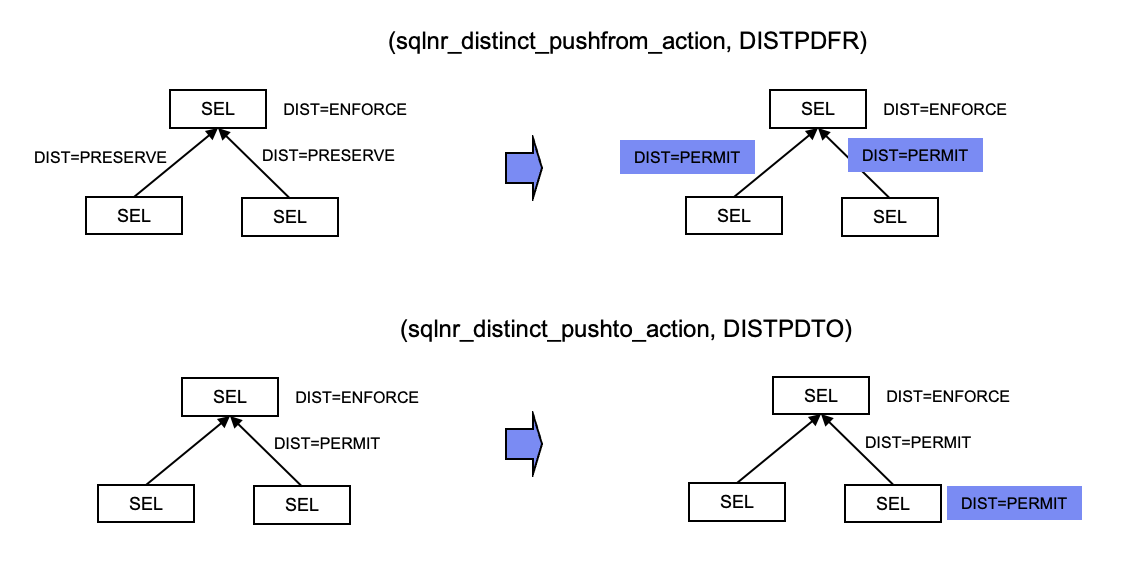
EorAPDFR(E or A Distinct Pushdown From)

有EXISTS,IN,ANY,SOME和ALL操作的Box是对重复值不敏感的。
BOXCOPY(Common Subexpression Replication)

这个是处理公共子表达式,会复制多份Boxes
AddKeys(Add Keys)

两个SELECT boxes,如果上层range over下层的quantifier都是F属性,那么ADDKEYS RULE就可以保证他们的合并,在上层中加入下层Box的唯一Key或者主键保证消除Box后仍然去重,举例说明该转换过程,ADDKEYS后SELMERGE就可以合并该View到上层的SELECT box中,并且保留了起初在view里面的去重:
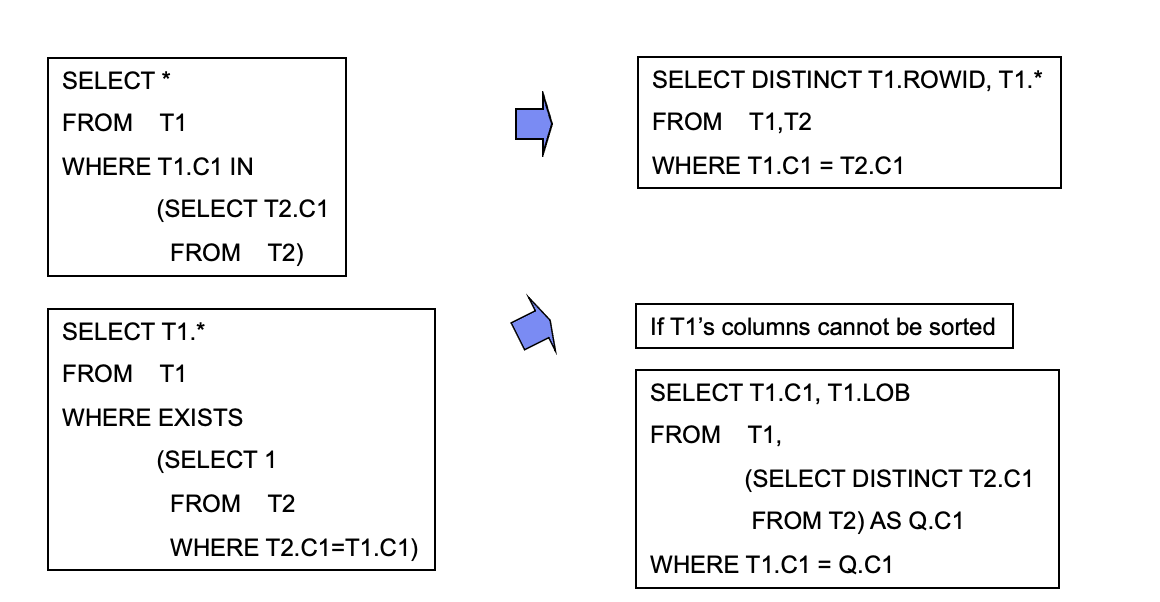
EtoF(E to F Quantifier Conversion)

该方法是将Existed子查询转换为查询表,即将quantifier的属性从E变成F,这样可以进行更多JOIN orders的尝试而带来性能提升,也可以带来额外的子查询合并。举例说明EtoF的转换,其中itp表含有唯一Key,因此无重复。
当然这个转换过程,DISTPU rule首先是吧出结果集是非重复的,其次利用 EtoF ruler来转换Existed子查询成为表后,最后通过SELMERGE RULE来合并Boxes,这样极大提升了性能。
下图形象的展示了EtoF的过程。
INT2EXIST(INTERSECT to Exists)

该RULE是将n维的INTERSECT操作转变为Existed子查询,最终可以通过RULE EtoF和SELMERGE规则合并为一个SELECT box。一般情况,数据库中INTERSECT操作都会用sort merge进行合并结果。当把INTERSECT转变为JOIN后,除了使用sort merge方法还可以利用JOIN方法来改进性能,带来很大提升。举例说明:
可扩展性的技术 |
并行技术 |
SQL功能丰富 |
|
|
|
Optimizer主要流程
生成/评估可选择的方式 |
可使用的实现方式 |
数据分布 (分布式环境) |
代价估算执行计划 |
选择最佳执行计划 |
Join、条件谓词和聚合操作 |
表扫描还是索引扫描,连接使用nested-loop join、sorted-merge join还是hash join |
节点间协调,数据转发、数据重分布、数据复制 |
结果集行数,CPU, I/O和内存的代价,通讯代价 |
计算整个资源消耗,运行时间 |
Optimizer主要输入
系统元数据信息 |
配置参数 |
存储设备特征 |
通讯带宽 |
内存资源 |
并发环境 |
定义及其约束条件,表、列和索引等的统计信息 |
CPU速率,由系统创建时确定,可计时程序 |
顺序访问和随机访问代价,表空间级别可以设置不同,查找和平均旋转延迟代价,传送率 |
在分布式环境中,将通信代价纳入总体代价 |
buffer pool(s)和sort heap等 |
平均用户访问 隔离级别和阻塞 可用锁数量 |
Optimizer三个层面
可选择执行策略 |
代价模型 |
搜索策略 |
基于规则的算子生成 生成可选方式:
|
行数,基于:
属性和代价
剪枝计划,如
|
Dynamic Programming vs. Greedy Bushy vs. Deep |
下图为DB2的访问方式的决策图:
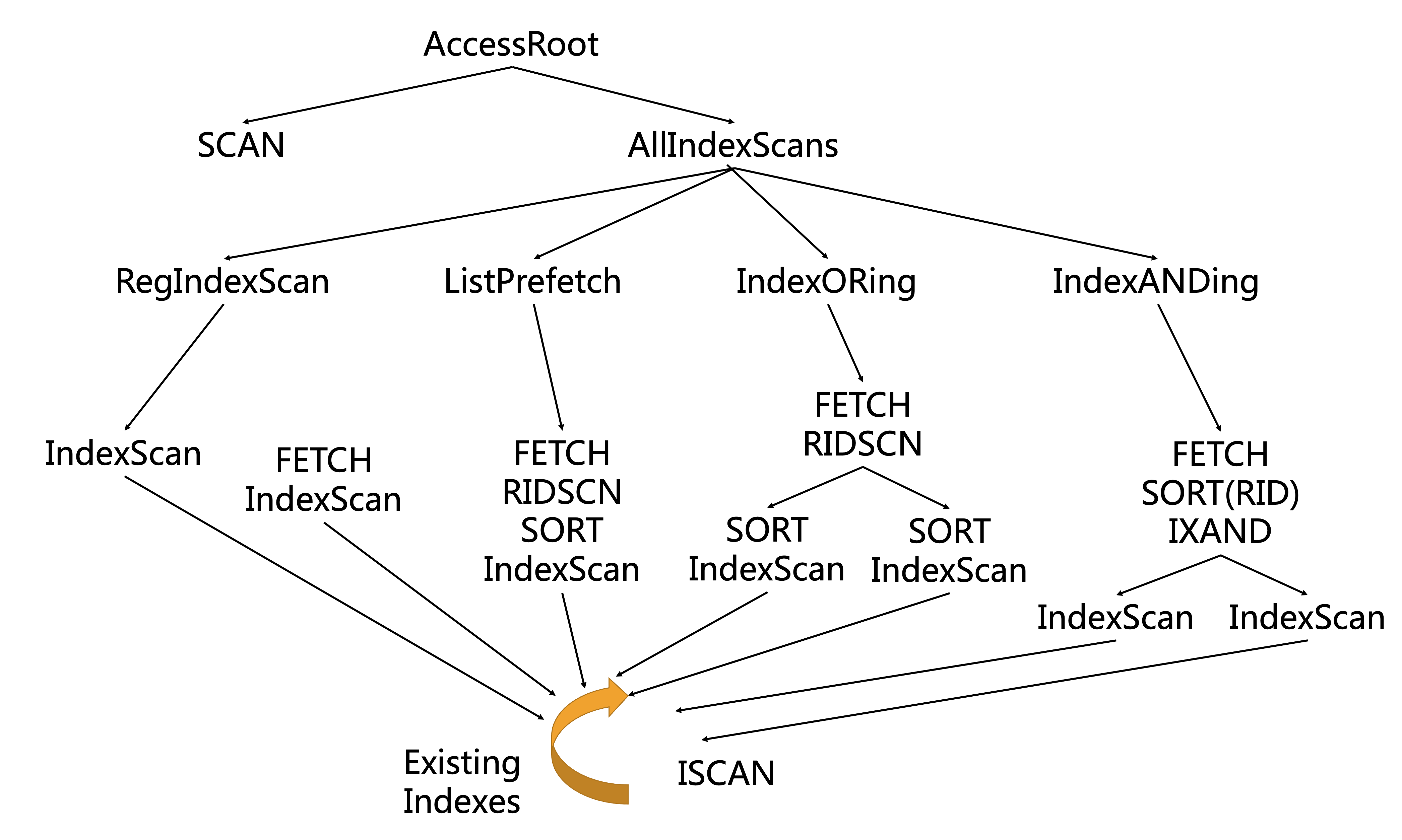
下图为DB2的连接方式的决策图:
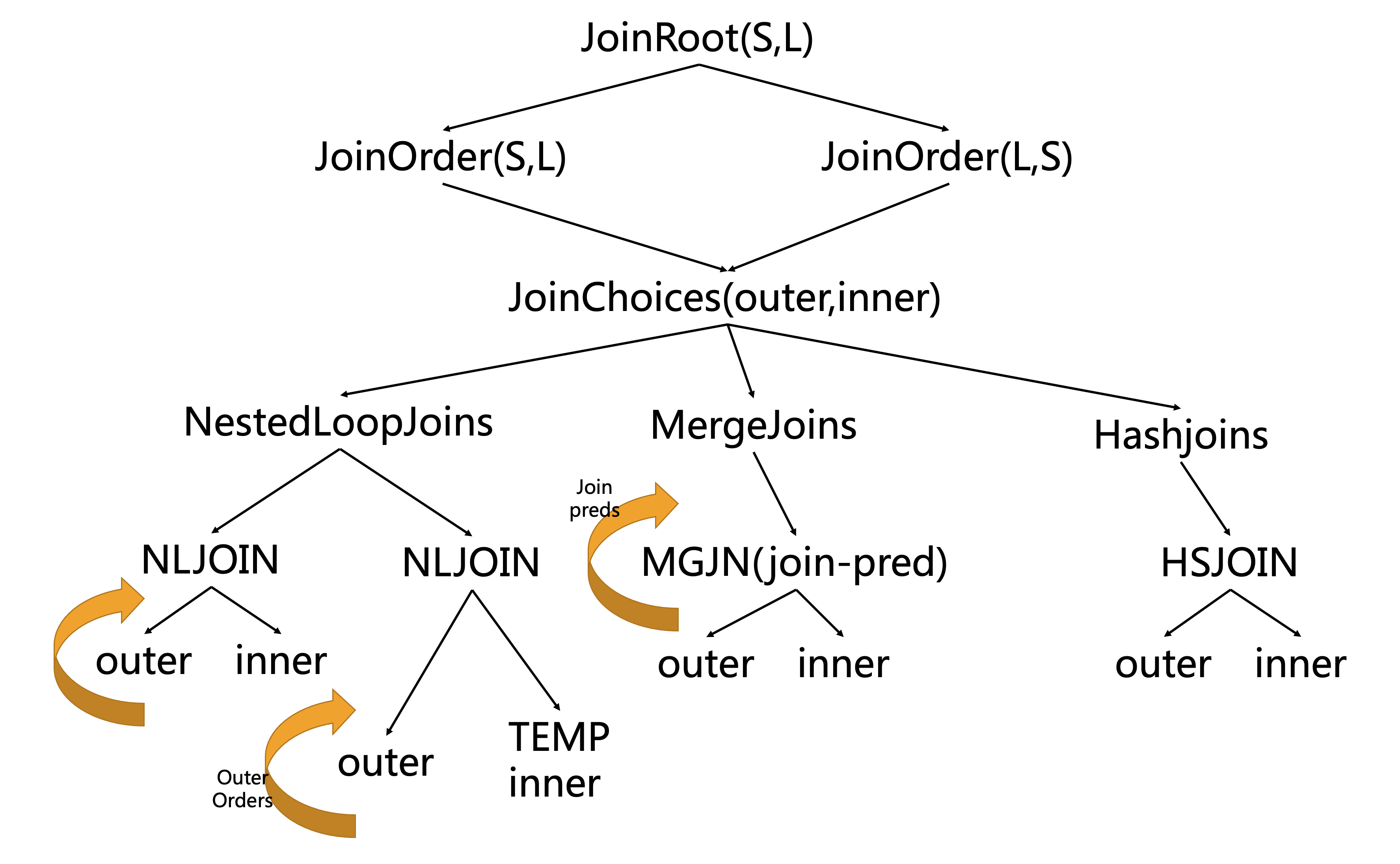
简单来说,DB2希望设计一套能够适应用户可以自定义的,交互式SQL而并非单一存储过程的一套灵活的,可扩展的,可生成多选择方式的优化器框架,来生成可执行的执行计划Plan,因此它先引入了一个最重要的原子对象LOw-LEvel Plan OPerator (LOLEPOP),读音有点和棒棒糖同音。LOLEPOP是数据库中的基本算子,可以在执行阶段进行解析执行,他们可以流式的操作和生成“表”数据,即火山模型执行。比如关系代数(Relational algebra )JOIN, UNION等,物理算子(Physical operators)SCAN, SORT, TEMP等。LOLEPOP又是一个带参数的函数的引用,如下图中的FETCH(<input stream>, Emp, {Name, Address}, )。
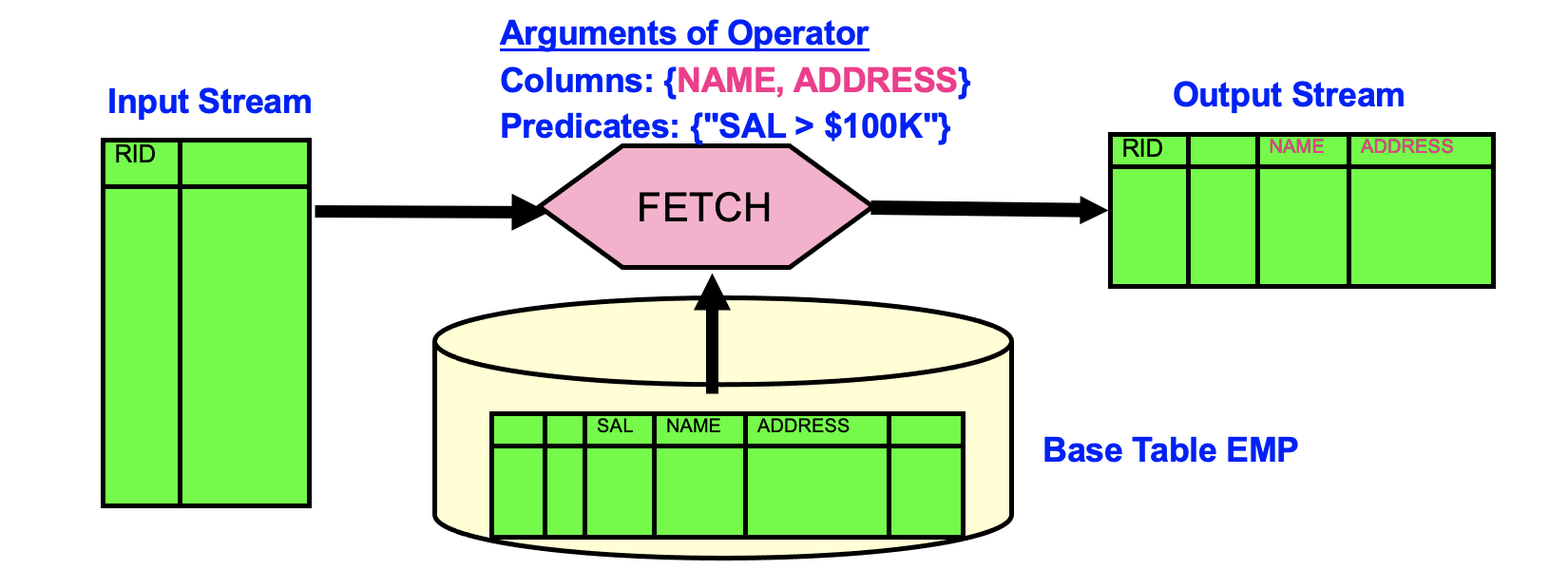
LOLEPOP组成了执行计划,下图我们可以看到最基本的一个Selected Plan,RETURN代表返回给客户端结果集
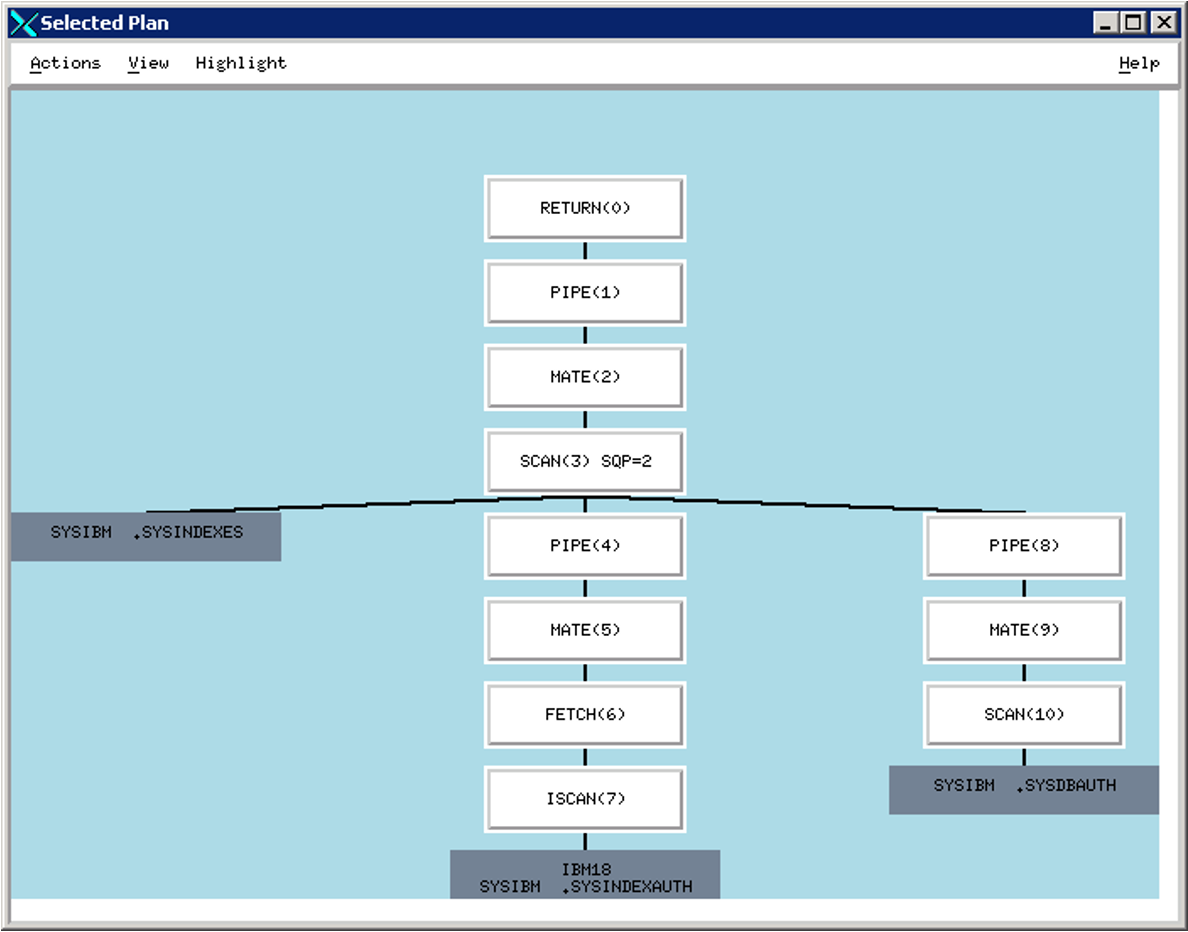
每个LOLEPOP都会有相应的属性,包括
Relational ("What?") |
Physical ("How?") |
Derived ("How much?") |
被访问的表 被访问的列 条件谓词 被引用的列 |
主键&唯一键 函数依赖 排序列 分区列(分布式) 远程对象类型和地址(联邦) |
基数Cardinality 最大可证明基数 估算代价,包括总代价,CPU的指令数,I/O访问,Re-scan代价,访问第一行代价(for OPTIMIZE FOR N ROWS) |
如图,点开ISCAN来查看上面的属性:

代价模型
不同的目标 |
合并估计 |
详细的模型数据 |
分布式中运行时间 OPTIMIZE FOR N ROWS 总资源 |
CPU 指令数(# of instructions) I/O访问方式代价 (random and sequential) 通信代价Communications (# of IP frames)包括节点间和不同服务器(联邦) |
是否需要buffer、是否可用及命中率 re-scan代价和build代价 预取代价和big-block的I/O代价 不均匀性数据考虑 操作系统 获取第一行代价(OPTIMIZE FOR N ROWS) |
基本统计信息 |
不均匀分布统计信息 |
聚合索引 |
用户自定义函数 统计信息 |
工具 |
表Rows/Pages 对于每一列:distinct values,平均长度和数据范围 对于每一个索引:key values, 层数,叶子节点数等等 |
N个最常见的值(默认10)适用于等式谓词 M个分位数(默认20)适用于范围谓词 Histogram N/M可以根据不同列来设置值 |
经验模型:I/O和buffer size的关系 考虑大缓冲区的带来的性能好处 |
在函数创建的时候,可以设定每次调用的I/O和CPU代价 |
可修改的统计信息 例如,UPDATE SYSSTAT.TABLES SET CARD = 1000000 优化器模拟器,可以模拟不存在的数据库(浅clone) 可以通过DB2LOOK获取表DDL和统计信息 |
可扩展策略
DB2是采取Bottom-up的方式来生成执行计划的,当然关于Top-down和Bottom-up的方式在当时也是一直讨论的比较激烈。常见采取Bottom-up的方式有System R, DB2, Oracle, Informix等,通过动态规划+广度优先算法找到最佳的执行计划。常见Top-down的方式有Volcano、Cascades、Tandem、SQL Server等,算子可能需要特定的属性,比如排序或者分区,可以有更好的空间剪枝和Rule扩展能力。当然DB2仍然选择的是Bottom-up,不过在预处理过程中增加了"Interesting" orders属性为joins、GROUP BY、ORDER BY的后续优化,"Interesting" partitions属性为分布式环境的后续优化,利用"un-interesting"属性来进行剪枝(比如No part interesting)。DB2增加了get_best_plan来实现Top-down设定这些属性,从而解决了找到最佳执行计划的方式。
DB2的优化策略采用了可以参数化的方式,一共可以有9级Level。0、1、2级采用贪婪算法:0是最小优化策略,主要是为了OLTP设计的优化,通常采用索引扫描和Nested-Loop Join,避免了一些查询改写,非常类似于MySQL的方式;1是次优化策略,大约在DB2 version 1的优化水平,当然没给出具体的描述;2是全面优化+限制搜索空间和时间方式,包括查询转换和类似Level 7的Join策略。3、5、7、9是采取动态规划的方式:3采用适中的优化策略,大约在DB2 MVS/ESA的优化水平,也没给出具体描述;5采用调整的全面优化,采用了所有的启发式技术;7是全面的优化策略,但是没有使用启发式的调整;9是最大优化策略,考虑所有的连接顺序,包括笛卡尔积这种连接方式。DB2还提供了自定义搜索空间的接口方便扩展。
并行考虑
DB2并行从I/O并行(数据条带化)、节点内并行(SMPs)和节点外并行(Shared Nothing)方面考虑。先来聊下I/O并行,DB2是通过创建基于containers(磁盘介质路径)上的逻辑tablespaces(对应mysql只有物理tablespaces的概念)来拆分数据存储的位置、table对象通过每次扩展extents来进行扩展容量,prefetch I/O支持并行I/O请求三个手段来实现I/O的并行加速。
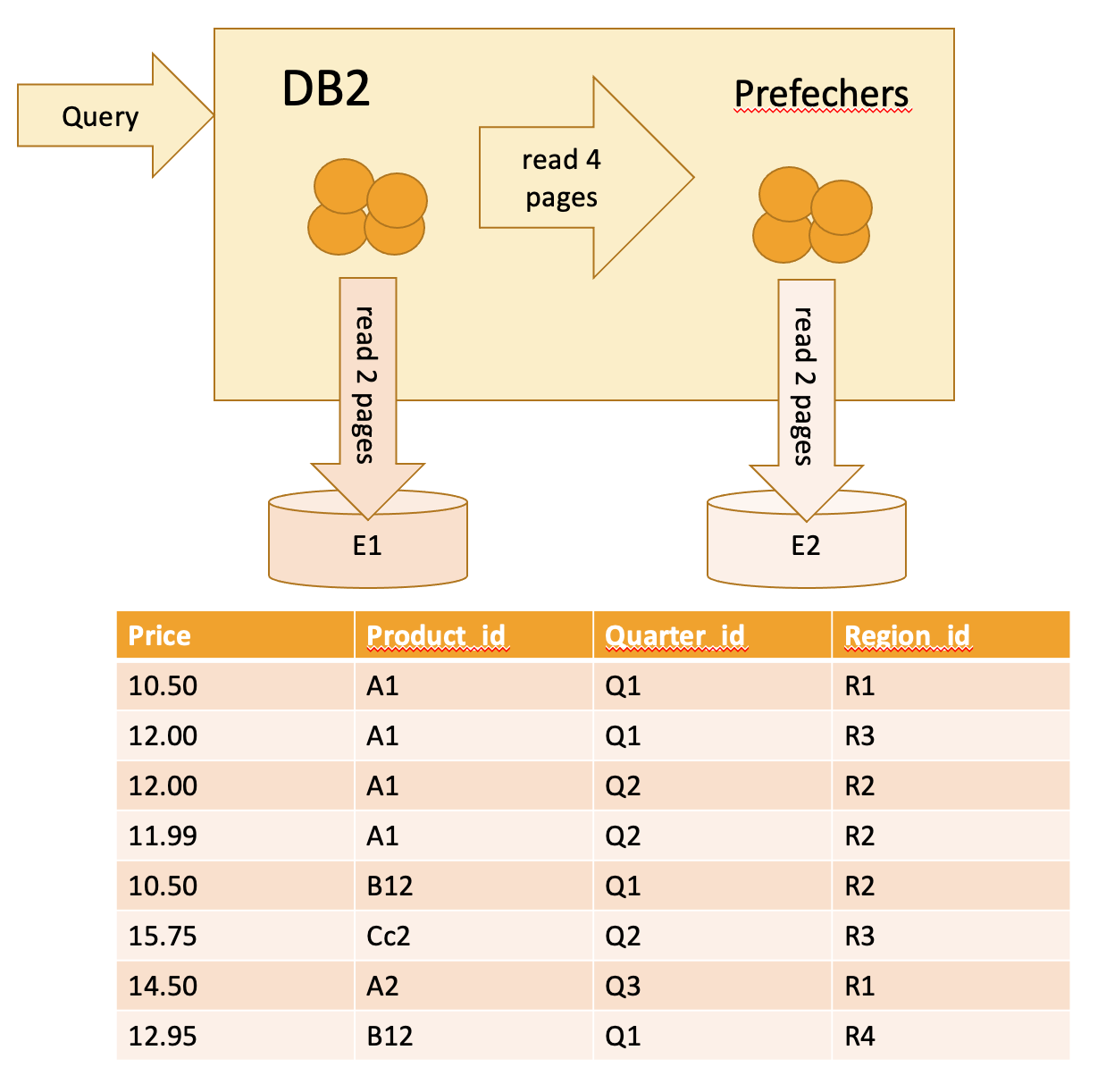
接下来聊的是DB2的节点内并行。DB2有非常完美的process model架构,有机会下篇文章来介绍DB2如何通过透明的并行process model机制实现一套代码支持serial、mpp、purescale、blue等架构。节点内并行类似于PolarDB MySQL的并行计算,利用多核技术来实现查询的加速。优化器能够支持生成对应的并行执行计划,执行器能够支持并行计算的数据收集、复制和交换等操作算子。
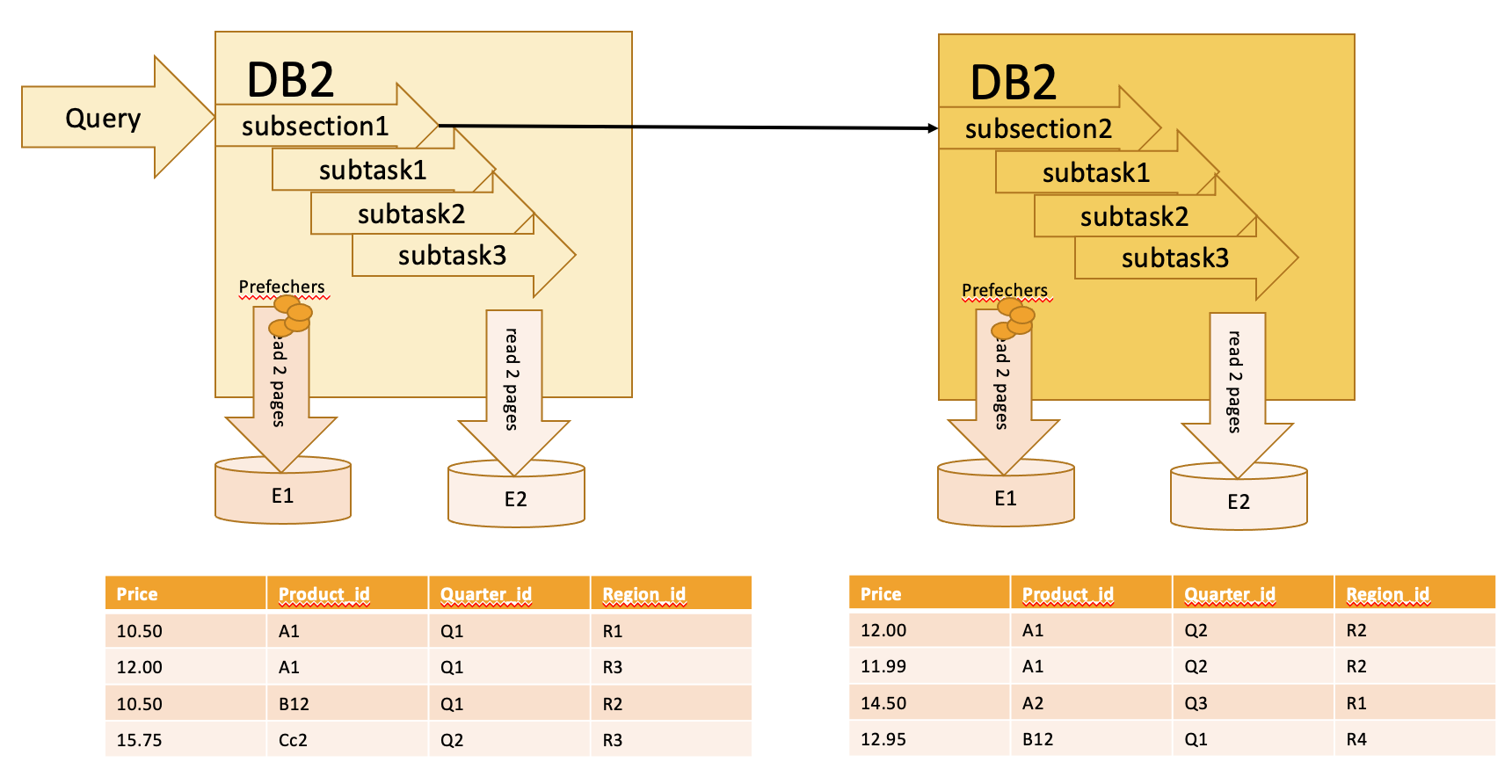
DB2节点间并行即MPP架构,各个节点mode是通过高速网络RDMA进行通讯的,DB2还支持逻辑节点node,节点间的CPU、内存和存储都是独立的。
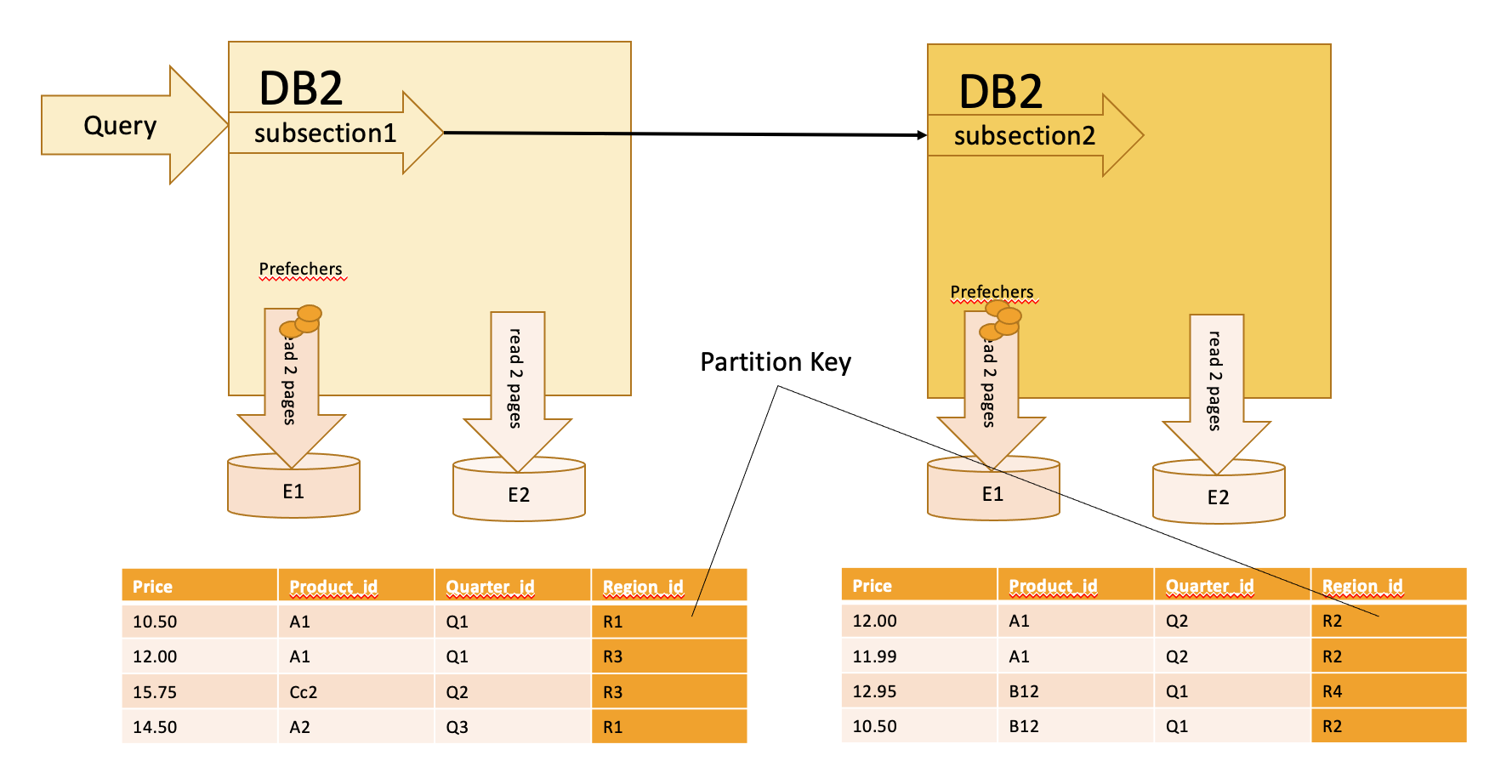
如何进行节点间并行的优化?主要是基于下面几个方面,数据如何拆分、查询的语义支持、动态重分布数据能力,最小时间消耗,本文不再详细讲述这块。
DB2会针对OLAP或BI系统增加特殊考虑。为什么要考虑特殊的优化策略?也很简单,就是避免笛卡尔积的连接,尤其是针对无连接条件的多表连接场景,也是我们常说的fact/dimension表。Oracle也有star transfermation的查询转换。这种优化大大减少了中间结果的级联放大。例如,举例下面场景:

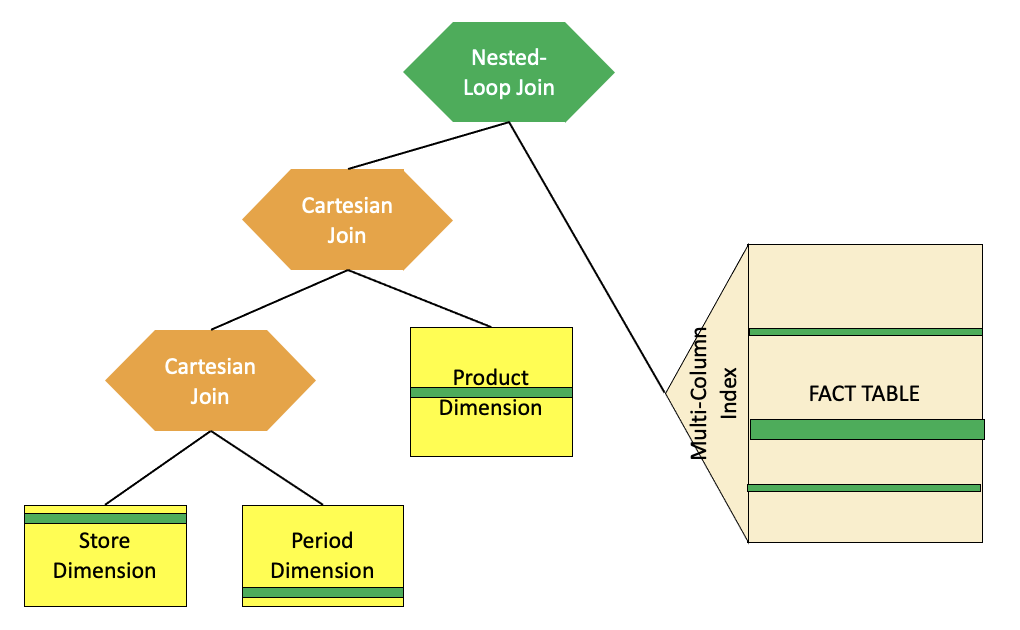
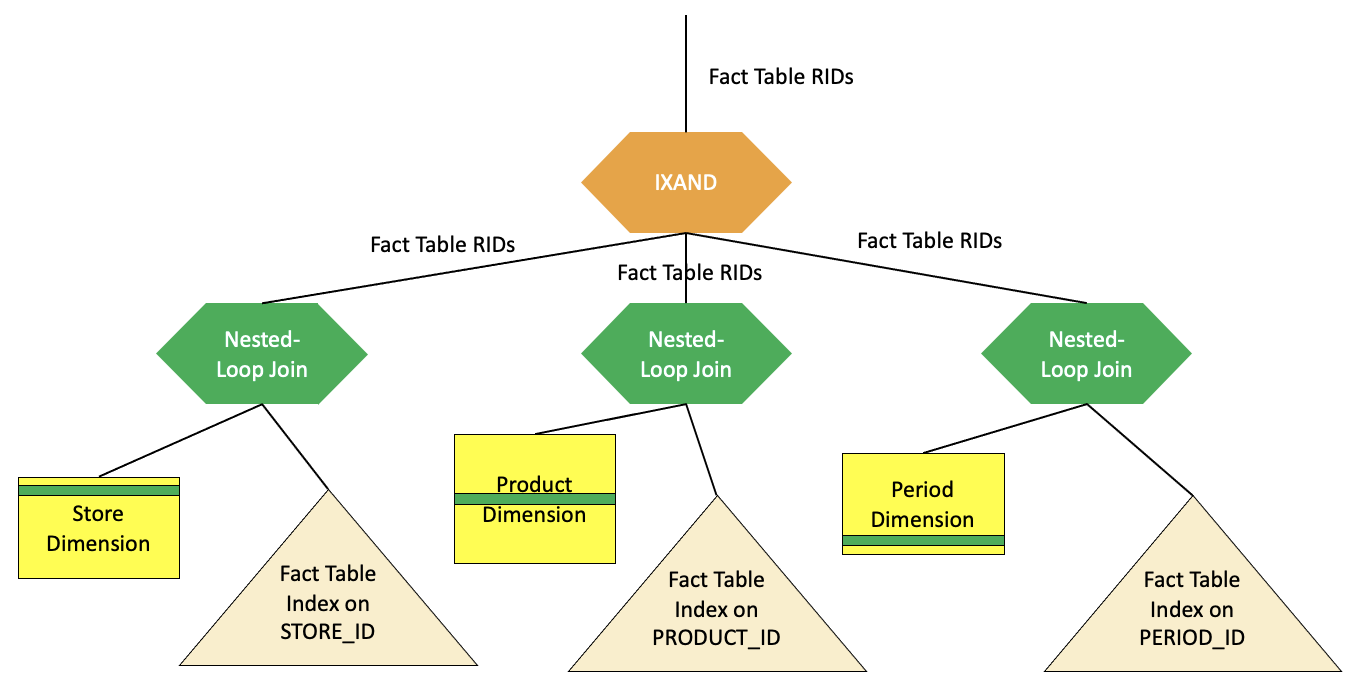
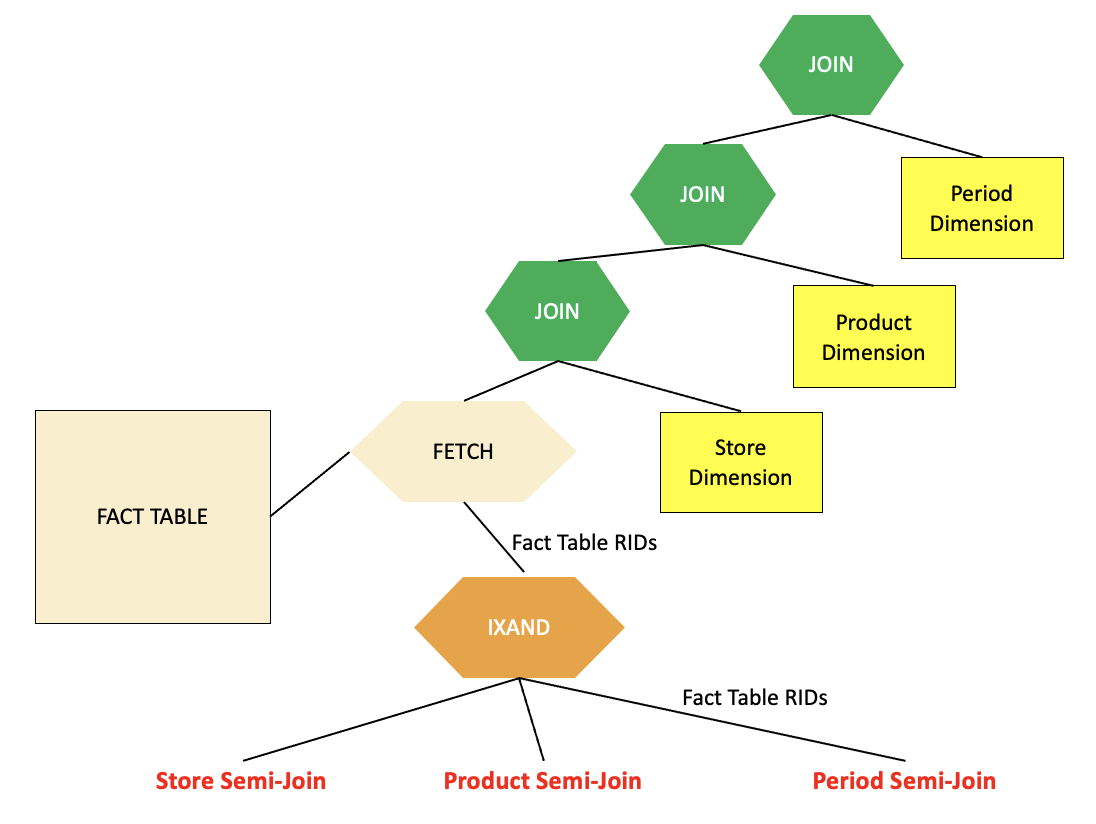
这篇文章详细介绍了DB2整个优化器的详细设计和运行过程,里面涉及到当时很多IBM和数据库业界古老的论文都在参考资料里,笔者也都是囫囵吞枣的阅读和理解,文中有不到位的地方,欢迎大家指正交流,希望后续还会给大家带来更多DB2的故事,如执行器和进程模型,联邦架构等等。
The History and Growth of IBM's DB2
DB2 Query Optimizer Information Center
Extensible/Rule Based Query Rewrite Optimization in Starburst
A Rule Engine for Query Transformation in Starburst and IBM DB2 C/S DBMS
Query Optimization in the IBM DB2 Family
Heterogeneous Database Query Optimization in DB2 Universal DataJoiner
Grammar-like Functional Rules for Representing Query Optimization Alternatives
Implementing an Interpreter for Functional Rules in a Query Optimizer
Improved Histograms for Selectivity Estimation of Range Predicates
Measuring the Complexity of Join Enumeration in Query Optimization
Extensible Query Processing in Starburst
Measuring the Complexity of Join Enumeration in Query Optimization
Estimating Compilation Time of a Query Optimizer


