400-123-4657


作者:佚名 时间:2024-08-12 02:44:41
参考博文:
码农王小呆:https://blog.csdn.net/manong_wxd/article/details/78735439
深度学习最全优化方法总结:
https://blog.csdn.net/u012759136/article/details/52302426
超级详细每个算法的讲解,可参考:
https://blog.csdn.net/tsyccnh/article/details/76673073
θ=θ?ηθJ(θ)
每迭代一步,都要用到训练集的所有数据,每次计算出来的梯度求平均
η代表学习率LR
θ=θ?ηθJ(θ;x(i);y(i))
通过每个样本来迭代更新一次,以损失很小的一部分精确度和增加一定数量的迭代次数为代价,换取了总体的优化效率的提升。增加的迭代次数远远小于样本的数量。
缺点:
对于参数比较敏感,需要注意参数的初始化
容易陷入局部极小值
当数据较多时,训练时间长
每迭代一步,都要用到训练集所有的数据。
θ=θ?ηθJ(θ;x(i:i+n);y(i:i+n))
为了避免SGD和标准梯度下降中存在的问题,对每个批次中的n个训练样本,这种方法只执行一次更新。【每次更新全部梯度的平均值】
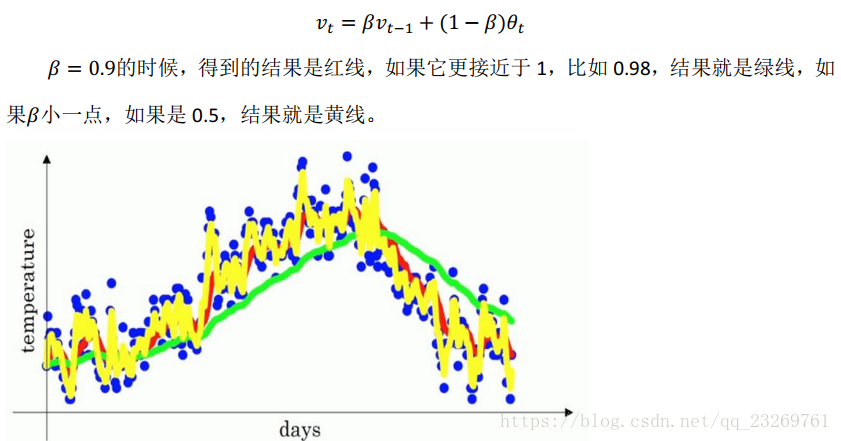

从这里我们就可已看出指数加权平均的名称由来,第100个数据其实是前99个数据加权和,而前面每一个数的权重呈现指数衰减,即越靠前的数据对当前结果的影响较小
缺点:存在开始数据的过低问题,可以通过偏差修正,但是在深度学习的优化算法中一般会忽略这个问题
当t不断增大时,分母逐渐接近1,影响就会逐渐减小了
优点:【相较于滑动窗口平均】
1.占用内存小,每次覆盖即可
2.运算简单
momentum是模拟物理里动量的概念,积累之前的动量来替代真正的梯度。公式如下:

然而网上更多的是另外一种版本,即去掉(1-β)
相当于上一版本上本次梯度的影响权值*1/(1-β)
两者效果相当,只不过会影响一些最优学习率的选取
优点
即在正确梯度方向上加速,并且抑制波动方向张的波动大小,在后期本次计算出来的梯度会很小,以至于无法跳出局部极值,Momentum方法也可以帮助跳出局部极值
参数设置
β的常用值为0.9,即可以一定意义上理解为平均了前10/9次的梯度。
至于LR学习率的设置,后面所有方法一起总结吧

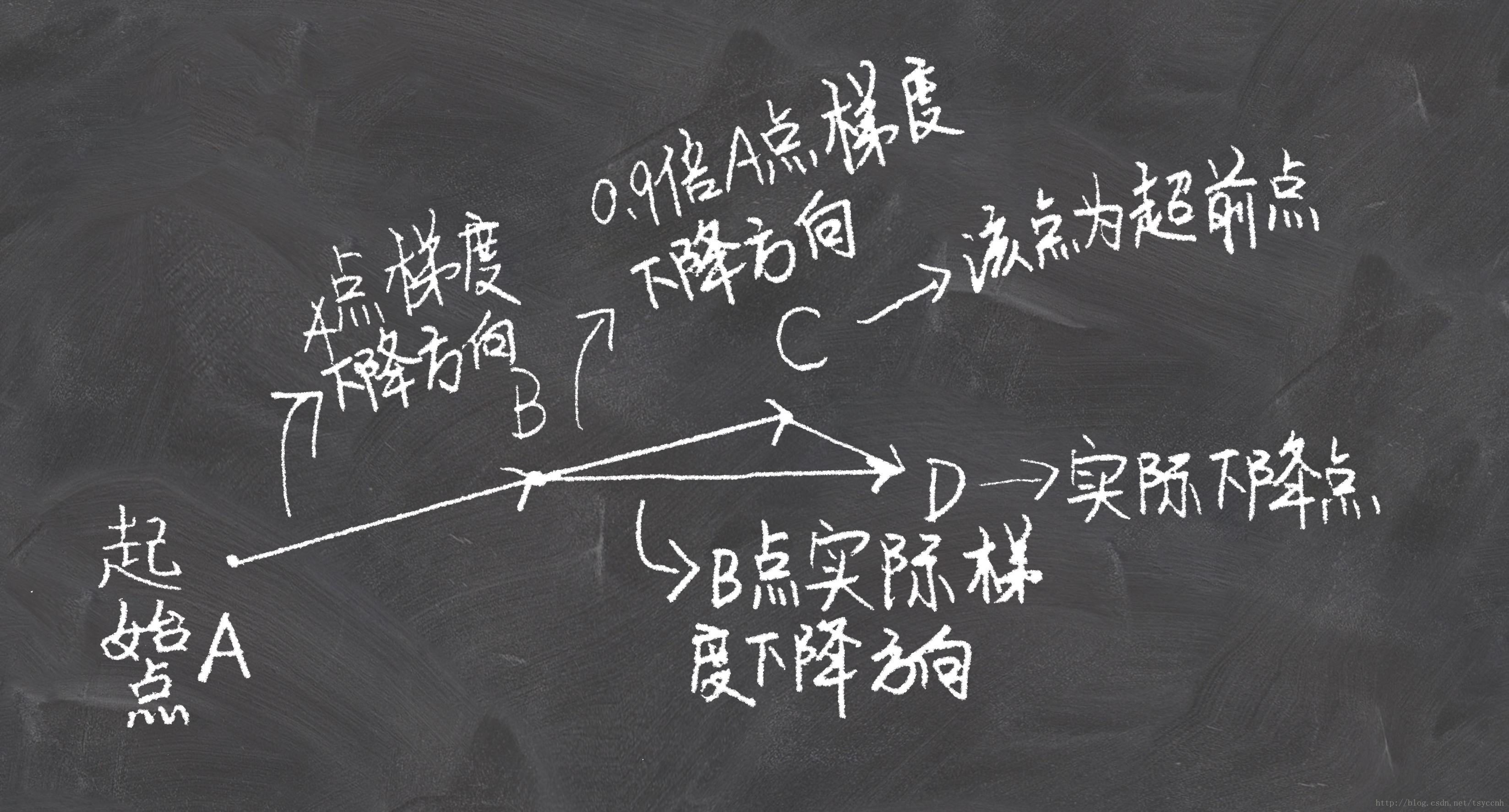

优点:
这种基于预测的更新方法,使我们避免过快地前进,并提高了算法地响应能力,大大改进了 RNN 在一些任务上的表现【为什么对RNN好呢,不懂啊】
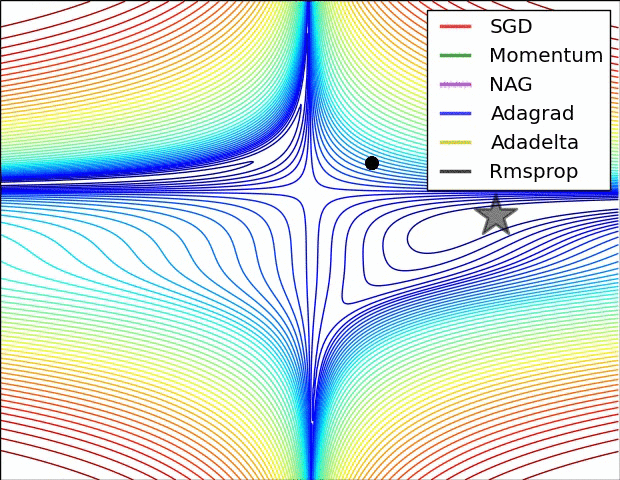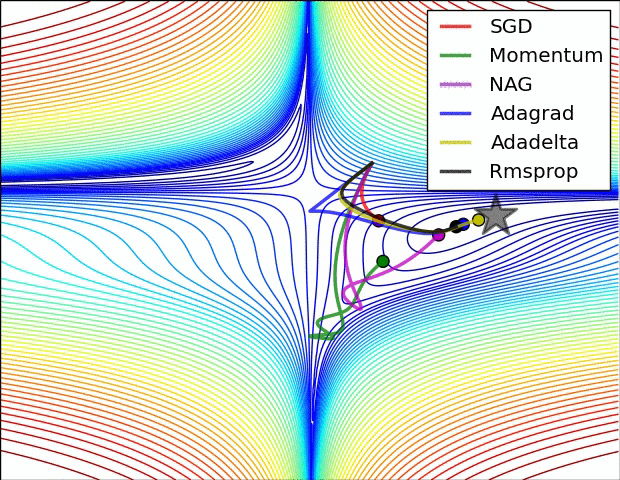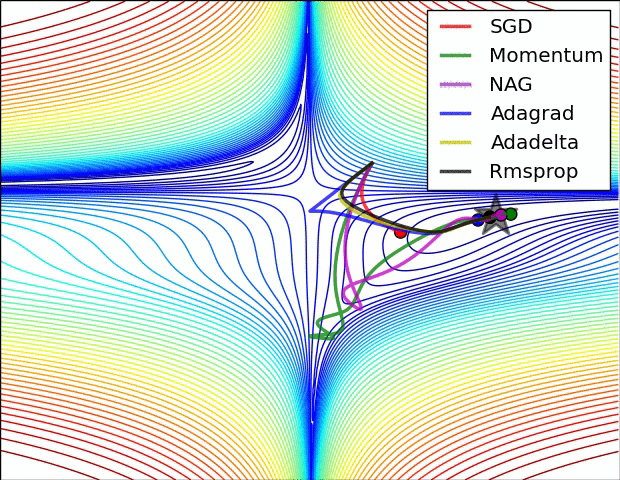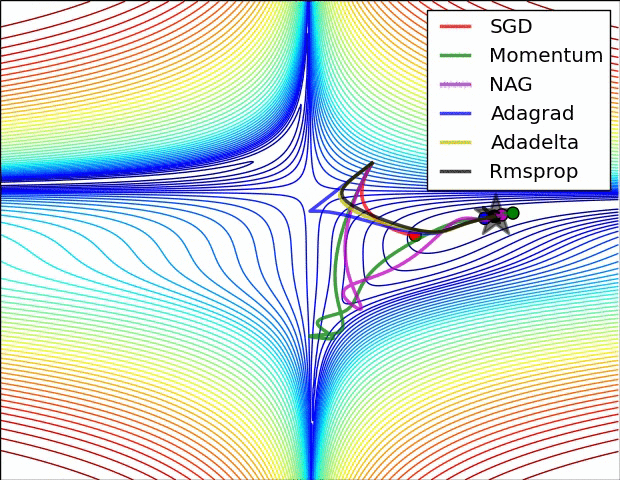
没有对比就没有伤害,NAG方法收敛速度明显加快。波动也小了很多。实际上NAG方法用到了二阶信息,所以才会有这么好的结果。先按照原来的梯度走一步的时候已经求了一次梯度,后面再修正的时候又求了一次梯度,所以是二阶信息。
参数设置:
同Momentum
其实,momentum项和nesterov项都是为了使梯度更新更加灵活,对不同情况有针对性。但是,人工设置一些学习率总还是有些生硬,接下来介绍几种自适应学习率的方法
前面的一系列优化算法有一个共同的特点,就是对于每一个参数都用相同的学习率进行更新。但是在实际应用中各个参数的重要性肯定是不一样的,所以我们对于不同的参数要动态的采取不同的学习率,让目标函数更快的收敛。
adagrad方法是将每一个参数的每一次迭代的梯度取平方累加再开方,用基础学习率除以这个数,来做学习率的动态更新。【这样每一个参数的学习率就与他们的梯度有关系了,那么每一个参数的学习率就不一样了!也就是所谓的自适应学习率】
优点:
参数设置:
只需要设置初始学习率,后面学习率会自我调整,越来越小
缺点:
Adagrad的一大优势时可以避免手动调节学习率,比如设置初始的缺省学习率为0.01,然后就不管它,另其在学习的过程中自己变化。当然它也有缺点,就是它计算时要在分母上计算梯度平方的和,由于所有的参数平方【上述公式推导中并没有写出来是梯度的平方,感觉应该是上文的公式推导忘了写】必为正数,这样就造成在训练的过程中,分母累积的和会越来越大。这样学习到后来的阶段,网络的更新能力会越来越弱,能学到的更多知识的能力也越来越弱,因为学习率会变得极其小【就会提前停止学习】,为了解决这样的问题又提出了Adadelta算法。
Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项【其实就是相当于指数滑动平均,只用了前多少步的梯度平方平均值】,并且也不直接存储这些项,仅仅是近似计算对应的平均值【这也就是指数滑动平均的优点】

优点:
不用依赖于全局学习率了
训练初中期,加速效果不错,很快
避免参数更新时两边单位不统一的问题
缺点:
训练后期,反复在局部最小值附近抖动

特点:
Adam = Adaptive + Momentum,顾名思义Adam集成了SGD的一阶动量和RMSProp的二阶动量。

特点:
提速可以归纳为以下几个方面:
- 使用momentum来保持前进方向(velocity);
- 为每一维参数设定不同的学习率:在梯度连续性强的方向上加速前进;
- 用历史迭代的平均值归一化学习率:突出稀有的梯度;
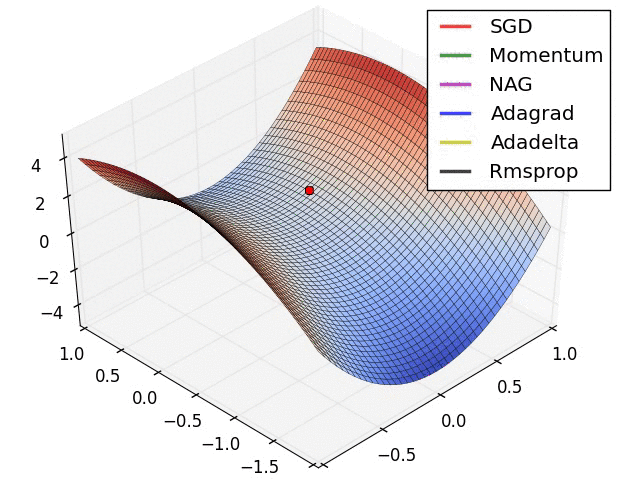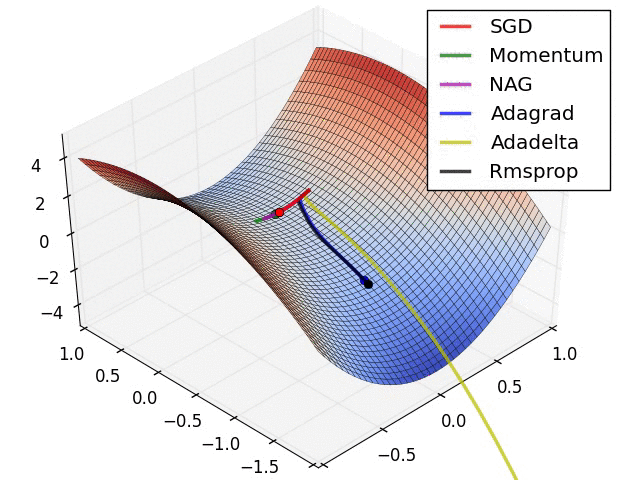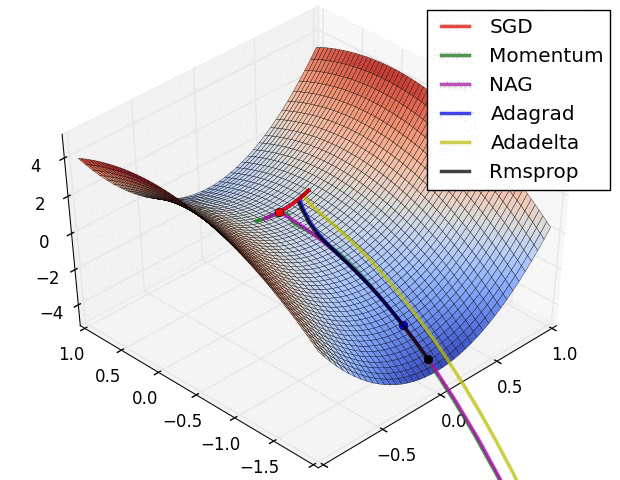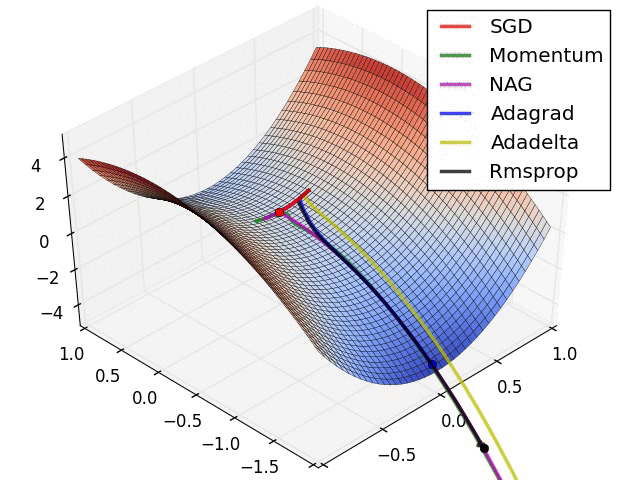
训练集较小【<2000】:直接使用batch梯度下降,每次用全部的样本进行梯度更新
训练集较大:batch_size一般设定为[64,512]之间,设置为2的n次方更符合电脑内存设置,代码会运行快一些
此外还要考虑GPU和CPU的存储空间和训练过程的波动问题
batch_size越小,梯度的波动越大,正则化的效果也越强,自然训练速度也会变慢,实验时应该多选择几个batch_size进行实验,以挑选出最优的模型。
加速收敛 2. 防止过拟合 3. 防止局部最优
在构建神经网络模型时,选择出最佳的优化器,以便快速收敛并正确学习,同时调整内部参数,最大程度地最小化损失函数。